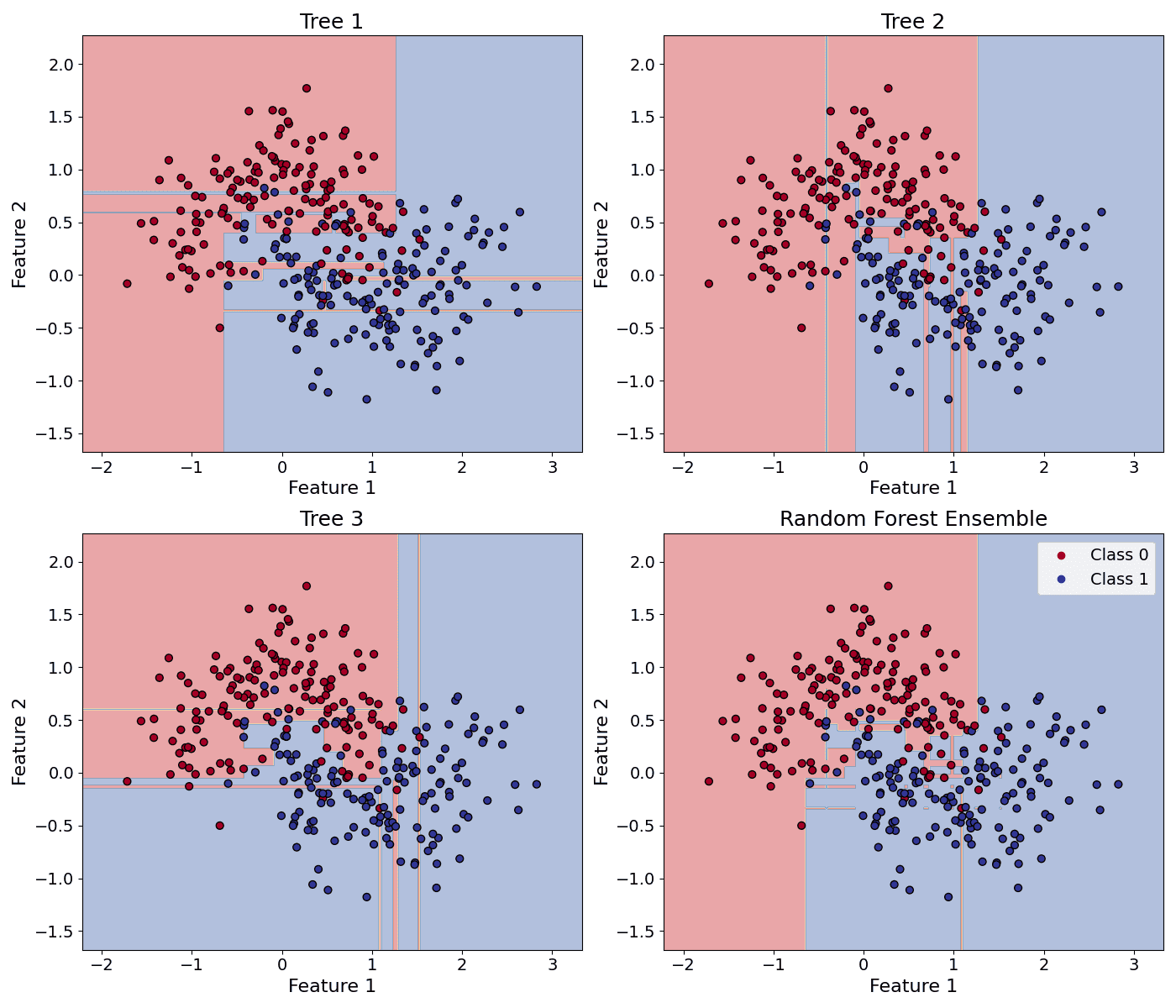
How to choose the number of features in a random forest?
Answer
Select the number of features ( ) using rules of thumb (default heuristics), then tune via cross-validation or out-of-bag (OOB) error to find the best value for your specific dataset.
) using rules of thumb (default heuristics), then tune via cross-validation or out-of-bag (OOB) error to find the best value for your specific dataset.
Default Heuristics:
Classification: 
Regression: 
Where: = total number of features, = number of features considered at each split.
= total number of features, = number of features considered at each split.
Bias-Variance Trade-off:
(1) Smaller max_features will increase randomness, leading to less correlated trees (reducing variance) but potentially higher bias.
(2) Larger max_features will decrease randomness, leading to more correlated trees (increasing variance) but potentially lower bias.
Grid Search/Randomized Search:
This is the most robust method. Define a range of possible max_features values and use cross-validation to evaluate the model’s performance for each value.
Out-of-Bag (OOB) Error:
Random Forests can estimate the generalization error internally using OOB samples. You can monitor the OOB error as you vary max_features to find the optimal value.
The figure below shows the cross-validation accuracy curve when using different numbers of features.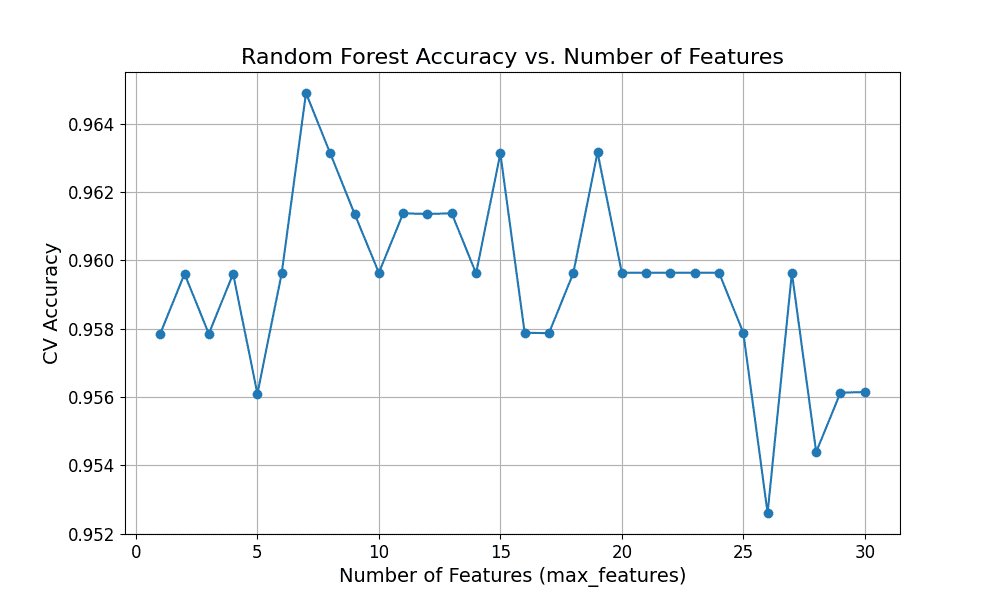

 = prediction of the b-th tree.
= prediction of the b-th tree. = total number of trees.
= total number of trees.