Without activation functions, how does the model capacity of a 2‑layer neural network compare to a 20‑layer network?
Answer
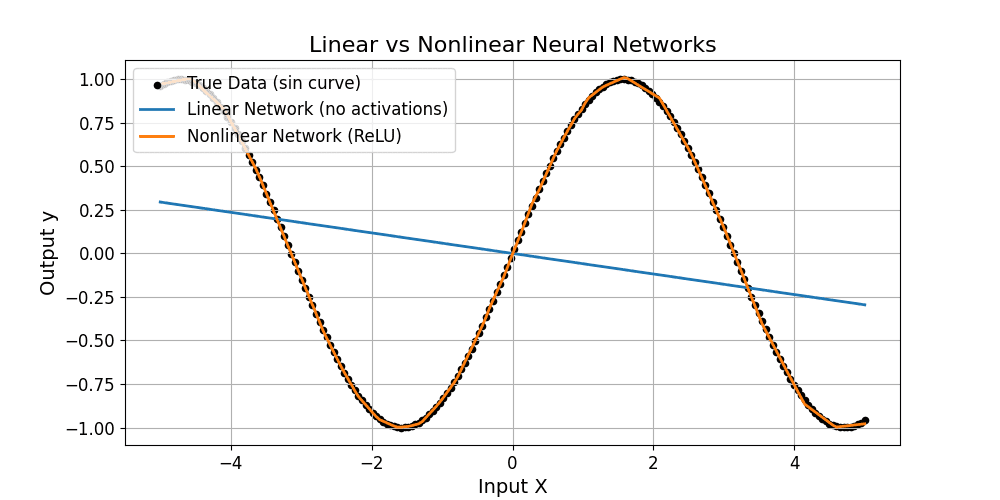
In the absence of activation functions, a neural network, regardless of depth, is equivalent to a single linear transformation. The model capacity is limited by the expressiveness of linear mappings, with the maximum rank determined by layer widths and thus the parameter count. The network with more parameters, whether 2-layer or 20-layer, can represent a higher-rank transformation, but depth alone provides no additional ability to capture non-linear relationships.
Without activation functions, all layers collapse to a single linear transformation:
Where:  is the effective weight matrix.
is the effective weight matrix. is the effective bias.
is the effective bias.
Representational capacity is the same for both 2-layer and 20-layer networks.
Parameter count also depends on the width of layers, not just depth.
Formula for fully connected layers:
Where:  is the input dimension.
is the input dimension. is the output dimension of that layer.
is the output dimension of that layer.
A wider 2-layer network can have more parameters than a narrow 20-layer network. Conversely, a sufficiently deep 20-layer network can have more parameters than a narrow 2-layer network.
Neither network can model nonlinear data, as shown below.