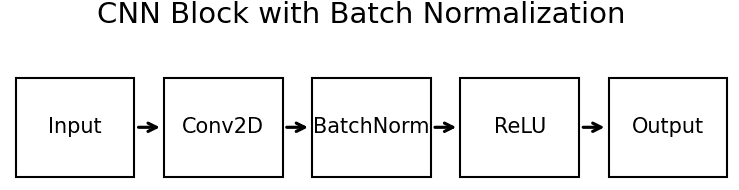
What is Group Normalization?
Answer
Group Normalization normalizes each sample independently by dividing its channels into groups and computing a mean and variance over the channels and spatial positions within each group. The normalized activations then receive learned per-channel scale and shift parameters. Because its statistics do not depend on other examples, GroupNorm behaves consistently with very small or variable batch sizes and uses the same computation during training and inference. The group count must be compatible with the channel count, and its inductive bias can be less suitable than BatchNorm when large, stable batches provide useful batch statistics.

Figure 1: A convolutional tensor is split into channel groups; each sample-group gets independent statistics before per-channel affine scaling.
(1) Per-Sample Statistics: Each example has its own group means and variances, so no running batch averages are required.
(2) Channel Grouping: For  channels and
channels and  groups, each group normalizes
groups, each group normalizes  values; channels within a group share statistics.
values; channels within a group share statistics.
(3) Boundary Cases:  normalizes all channels and spatial positions together, while
normalizes all channels and spatial positions together, while  gives one channel per group and resembles InstanceNorm.
gives one channel per group and resembles InstanceNorm.

Figure 2: Normalization families differ mainly in which batch, channel, and spatial axes share statistics and whether inference needs running estimates.
Mathematical Formulation:



Where:
 indexes samples,
indexes samples,  indexes channel groups, and
indexes channel groups, and  index channel and spatial position.
index channel and spatial position. is the set of activations in group of sample ;
is the set of activations in group of sample ;  indexes elements in that set.
indexes elements in that set. is the number of normalized values when
is the number of normalized values when  channels are divided into groups over height
channels are divided into groups over height  and width
and width  .
. and
and  are the group mean and variance;
are the group mean and variance;  and are input and normalized output activations.
and are input and normalized output activations. maps channel
maps channel  to its group,
to its group,  are learned per-channel scale and shift, and stabilizes division.
are learned per-channel scale and shift, and stabilizes division.
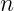 indexes samples,
indexes samples,  indexes channel groups, and
indexes channel groups, and  index channel and spatial position.
index channel and spatial position. is the set of activations in group
is the set of activations in group 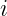 indexes elements in that set.
indexes elements in that set. is the number of normalized values when
is the number of normalized values when 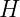 and width
and width  .
. and
and  are the group mean and variance;
are the group mean and variance; 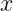 and
and  are input and normalized output activations.
are input and normalized output activations. maps channel
maps channel  to its group,
to its group,  are learned per-channel scale and shift, and
are learned per-channel scale and shift, and 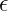 stabilizes division.
stabilizes division.
 = input feature,
= input feature, = mean of all features for the current sample,
= mean of all features for the current sample, = standard deviation of all features,
= standard deviation of all features, = small constant for numerical stability,
= small constant for numerical stability, = learnable scale and shift parameters.
= learnable scale and shift parameters.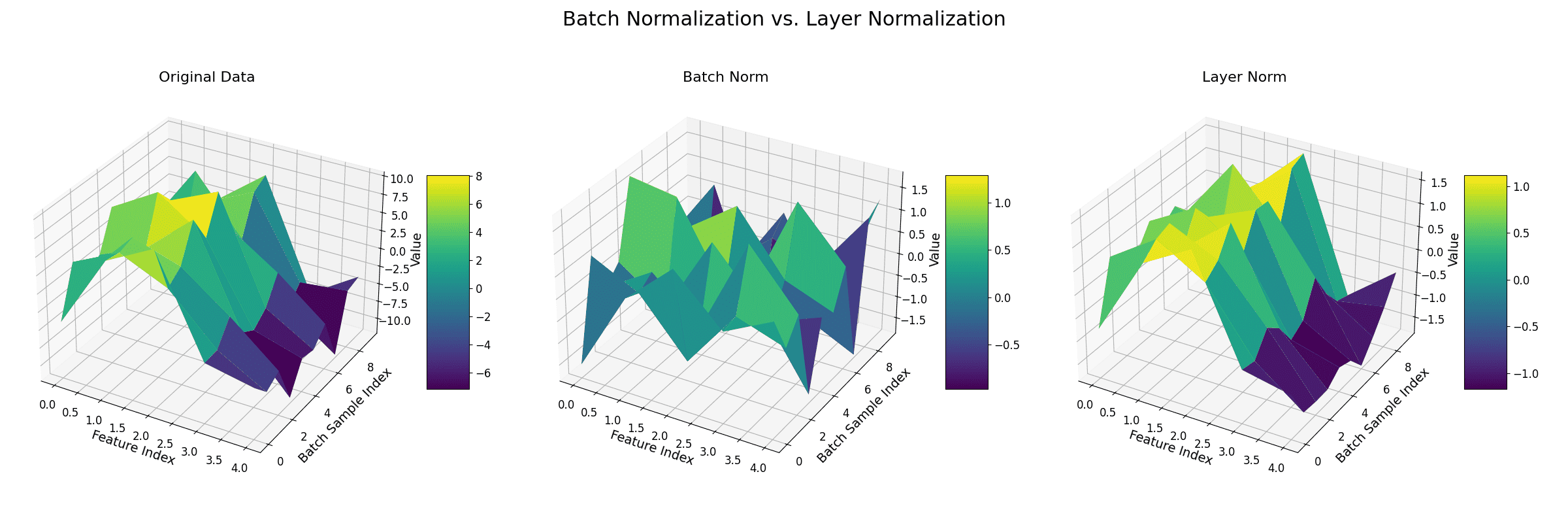
 for input
for input  :
:



 , channel
, channel  , height
, height  , and width
, and width  .
. is the height of the feature map (number of rows per channel).
is the height of the feature map (number of rows per channel). is the width of the feature map (number of columns per channel).
is the width of the feature map (number of columns per channel). is the mean of all spatial values in channel
is the mean of all spatial values in channel  is the variance of spatial values in channel
is the variance of spatial values in channel  is the normalized value after subtracting the mean and dividing by the standard deviation.
is the normalized value after subtracting the mean and dividing by the standard deviation. is a learnable scale parameter for channel
is a learnable scale parameter for channel  is a learnable shift parameter for channel
is a learnable shift parameter for channel 
 represents an individual feature value in the batch.
represents an individual feature value in the batch. represents the mean of that feature across the current batch.
represents the mean of that feature across the current batch. represents the variance of that feature across the current batch.
represents the variance of that feature across the current batch. ) added to the denominator for numerical stability.
) added to the denominator for numerical stability. 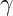 is a learnable scaling parameter.
is a learnable scaling parameter.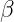 is a learnable shifting parameter.
is a learnable shifting parameter.