Why use batch normalization in deep learning training?
Answer
Batch normalization is a crucial technique during deep learning training that enhances network stability and accelerates learning. It achieves this by normalizing the inputs to the activation function for each mini-batch, specifically by subtracting the batch mean and dividing by the batch standard deviation.
After normalization, the layer applies a learnable scale (gamma) and shift (beta) that are updated during training to allow the network to recover the identity transformation if needed and to re-center/re-scale activations appropriately.
Here’s the formula for Batch Normalization:
Where: represents an individual feature value in the batch.
represents an individual feature value in the batch. represents the mean of that feature across the current batch.
represents the mean of that feature across the current batch. represents the variance of that feature across the current batch.
represents the variance of that feature across the current batch.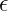 is a small constant (e.g.
is a small constant (e.g.  ) added to the denominator for numerical stability.
) added to the denominator for numerical stability. 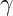 is a learnable scaling parameter.
is a learnable scaling parameter.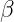 is a learnable shifting parameter.
is a learnable shifting parameter.
Batch Normalization is typically applied after the linear transformation of a layer (e.g., after the convolution operation in a convolutional layer) and before the non-linear activation function (e.g., ReLU).
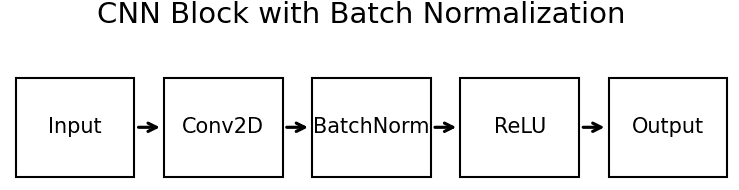
The benefits of using Batch Normalization include:
(1) Stabilizes learning: Reduces internal covariate shift, making training more stable and less sensitive to network initialization and hyperparameter choices.
(2) Enables higher learning rates and accelerates training: Allows for larger learning rates without causing instability, leading to faster convergence.
(3) Improves generalization: Normalizes each mini-batch independently, introducing noise into activations. This noise prevents over-reliance on specific mini-batch activations, forcing the network to learn more robust and generalizable features.
Leave a Reply