What is an LSTM (Long Short-Term Memory) network? How does it address vanishing gradients?
Answer
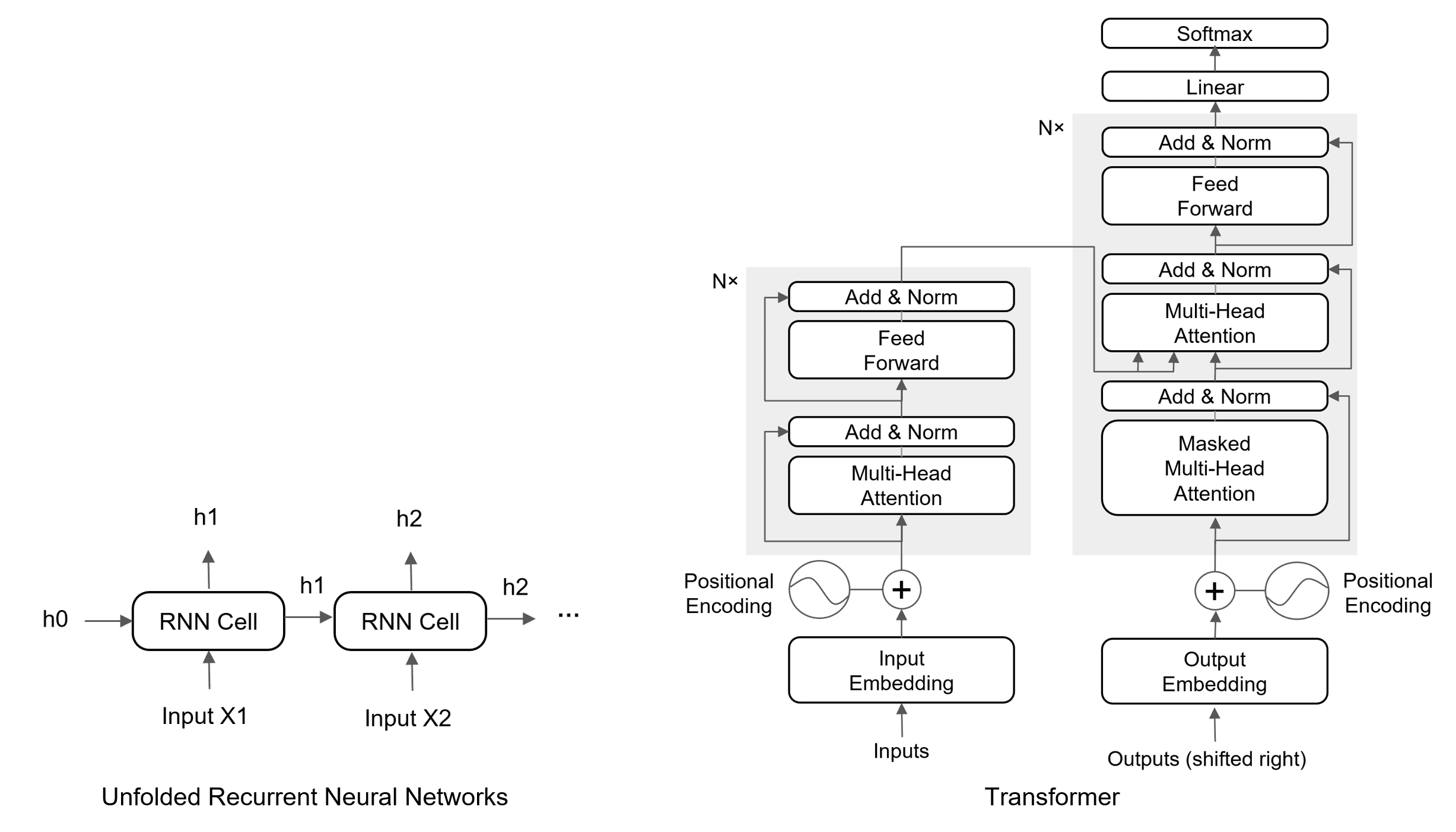
A Long Short-Term Memory network is a gated recurrent neural network designed to carry useful information across many sequence steps. Each cell maintains a cell state and uses forget, input, and output gates to control what is retained, written, and exposed. Its additive cell-state update creates a shorter gradient path than repeatedly multiplying through a vanilla RNN’s nonlinear state transition, so gradients can remain useful when forget gates stay near one. LSTMs mitigate vanishing gradients rather than eliminating them: saturated gates, long products of forget factors, and poor optimization can still weaken learning.

Figure 1: One LSTM timestep: gated reads and writes surround an additive cell-state highway, while the output gate produces the hidden state.
(1) Two Recurrent States: The cell state  is the long-term memory path, while the hidden state
is the long-term memory path, while the hidden state  is the exposed representation used by the next step and downstream layers.
is the exposed representation used by the next step and downstream layers.
(2) Gated Update: The forget gate scales old memory, the input gate controls a candidate update, and the output gate selects how much of the updated memory becomes visible.
(3) Gradient Preservation: The derivative along the direct cell-state path contains products of forget gates instead of repeated full recurrent Jacobians; values near one preserve gradient flow.
Mathematical Formulation:
![f_t=\sigma\!\left(W_f[x_t,h_{t-1}]+b_f\right)](https://s0.wp.com/latex.php?latex=f_t%3D%5Csigma%5C%21%5Cleft%28W_f%5Bx_t%2Ch_%7Bt-1%7D%5D%2Bb_f%5Cright%29&bg=ffffff&fg=000&s=3&c=20201002)
![i_t=\sigma\!\left(W_i[x_t,h_{t-1}]+b_i\right)](https://s0.wp.com/latex.php?latex=i_t%3D%5Csigma%5C%21%5Cleft%28W_i%5Bx_t%2Ch_%7Bt-1%7D%5D%2Bb_i%5Cright%29&bg=ffffff&fg=000&s=3&c=20201002)
![\tilde c_t=\tanh\!\left(W_c[x_t,h_{t-1}]+b_c\right)](https://s0.wp.com/latex.php?latex=%5Ctilde+c_t%3D%5Ctanh%5C%21%5Cleft%28W_c%5Bx_t%2Ch_%7Bt-1%7D%5D%2Bb_c%5Cright%29&bg=ffffff&fg=000&s=3&c=20201002)

![o_t=\sigma\!\left(W_o[x_t,h_{t-1}]+b_o\right)](https://s0.wp.com/latex.php?latex=o_t%3D%5Csigma%5C%21%5Cleft%28W_o%5Bx_t%2Ch_%7Bt-1%7D%5D%2Bb_o%5Cright%29&bg=ffffff&fg=000&s=3&c=20201002)

Where:
 is the timestep;
is the timestep;  is the current input, and
is the current input, and  are the previous hidden and cell states.
are the previous hidden and cell states. are element-wise forget, input, and output gates;
are element-wise forget, input, and output gates;  is the candidate cell update.
is the candidate cell update. is the updated long-term cell state and
is the updated long-term cell state and  is the exposed hidden state.
is the exposed hidden state. and
and  are learned affine parameters;
are learned affine parameters; ![[x_t,h_{t-1}]](data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSI1NyIgaGVpZ2h0PSIxNyIgdmlld0JveD0iMCAwIDU3IDE3Ij48cmVjdCB3aWR0aD0iMTAwJSIgaGVpZ2h0PSIxMDAlIiBzdHlsZT0iZmlsbDojY2ZkNGRiO2ZpbGwtb3BhY2l0eTogMC4xOyIvPjwvc3ZnPg==) denotes concatenation.
denotes concatenation. is sigmoid,
is sigmoid,  is hyperbolic tangent, and
is hyperbolic tangent, and  is element-wise multiplication; the direct derivative includes
is element-wise multiplication; the direct derivative includes  .
.
 is the timestep;
is the timestep;  is the current input, and
is the current input, and  are the previous hidden and cell states.
are the previous hidden and cell states. are element-wise forget, input, and output gates;
are element-wise forget, input, and output gates;  is the candidate cell update.
is the candidate cell update. and
and  are learned affine parameters;
are learned affine parameters; ![[x_t,h_{t-1}]](https://s0.wp.com/latex.php?latex=%5Bx_t%2Ch_%7Bt-1%7D%5D&bg=ffffff&fg=000&s=2&c=20201002) denotes concatenation.
denotes concatenation. is sigmoid,
is sigmoid,  is hyperbolic tangent, and
is hyperbolic tangent, and  is element-wise multiplication; the direct derivative includes
is element-wise multiplication; the direct derivative includes  .
.
Figure 2: Why LSTMs mitigate vanishing gradients: a vanilla RNN repeatedly multiplies full nonlinear Jacobians, whereas the LSTM provides a gated direct memory path.