What makes Transformers more parallel-friendly than RNNs?
Answer
The fundamental difference lies in their architecture: RNNs sequentially process data, with each step depending on the output of the previous one. Transformers, on the other hand, utilize attention to examine all parts of the sequence simultaneously, enabling parallel processing. This parallelizability is a key reason for the Transformer’s superior performance on many tasks and its dominance in modern natural language processing.
(1) No Temporal Dependency: Transformers process all input tokens simultaneously, unlike RNNs, which depend on previous hidden states.
(2) Self-Attention is Fully Parallelizable: Attention scores are computed for all positions in a single pass.
(3) Optimized for GPUs: Matrix multiplications in Transformers leverage GPU cores better than the sequential loops in RNNs.
The figure below demonstrates the architectures of RNNs and Transformers.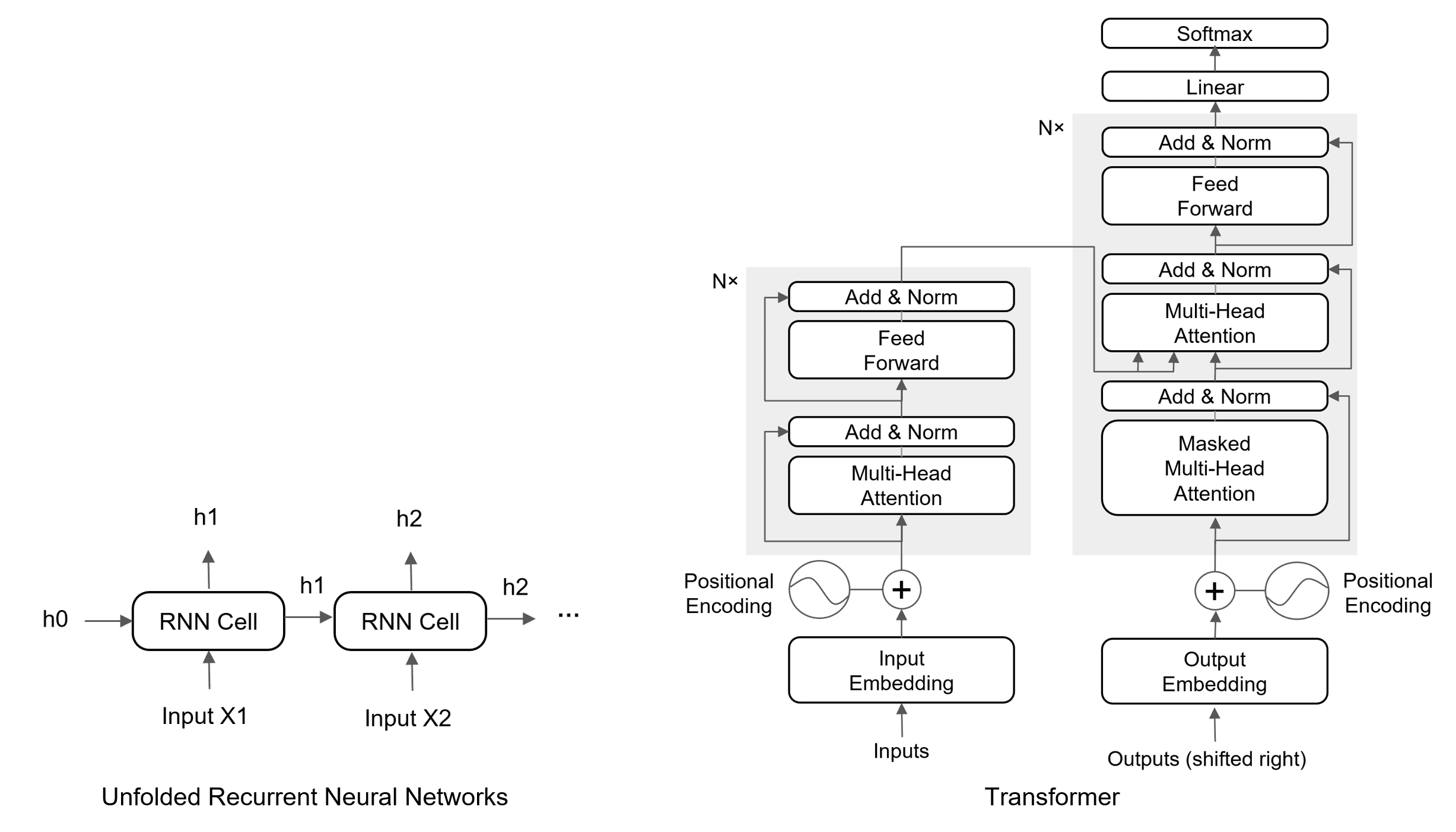
Leave a Reply