How does BERT’s pre-training objective differ from GPT’s?
Answer
BERT is trained primarily with masked language modeling: selected input tokens are corrupted, and a bidirectional encoder predicts the original tokens from visible context on both sides. GPT uses causal language modeling: a decoder predicts each next token using only earlier tokens, enforced by a triangular attention mask. MLM supplies loss only at selected positions and creates a corruption mismatch between pre-training and ordinary inputs, whereas causal modeling supplies a target at nearly every position and matches left-to-right generation. Original BERT also used next sentence prediction, while standard GPT pre-training relies on the autoregressive token objective rather than NSP.

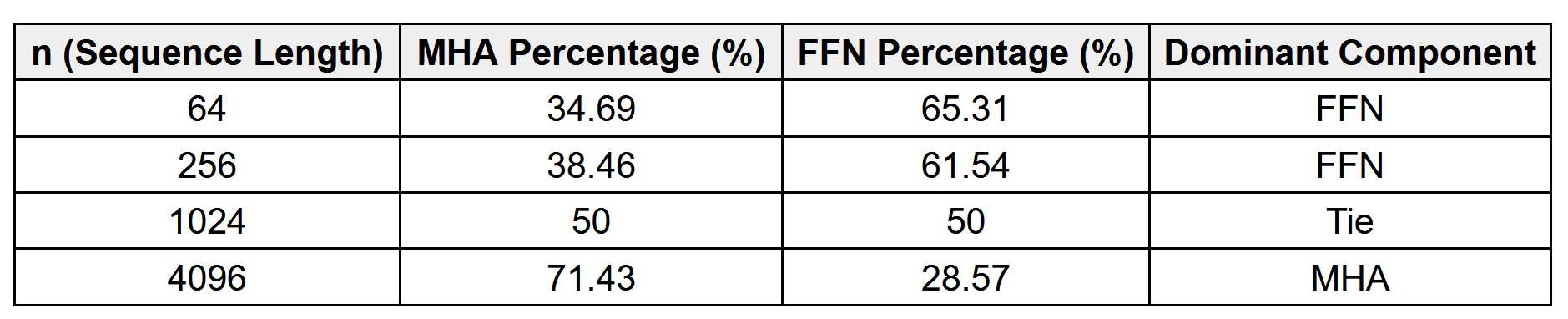
Figure 1: BERT reconstructs selected corrupted tokens from two-sided context, while GPT predicts the next token at every step from a left-only prefix.
(1) Context Visibility: BERT’s visible tokens attend bidirectionally; GPT position  cannot attend to positions later than .
cannot attend to positions later than .
(2) Prediction Targets: BERT reconstructs a selected masked subset, while GPT shifts the sequence and predicts the next token at each usable position.
(3) Downstream Bias: BERT naturally supports full-context understanding, whereas GPT’s objective directly trains open-ended autoregressive generation; either family can be adapted beyond that bias.
Mathematical Formulation:


Where:
 and
and  are the masked and causal language-modeling losses.
are the masked and causal language-modeling losses. is BERT’s selected target set and
is BERT’s selected target set and  indexes one target token
indexes one target token  .
. denotes BERT’s visible corrupted context outside the selected targets, and
denotes BERT’s visible corrupted context outside the selected targets, and  is the reconstruction probability.
is the reconstruction probability. indexes a GPT target position,
indexes a GPT target position,  is sequence length, and
is sequence length, and  is the preceding token prefix.
is the preceding token prefix. is the next-token probability and
is the next-token probability and  converts each probability into a log-likelihood term.
converts each probability into a log-likelihood term.
 and
and  are the masked and causal language-modeling losses.
are the masked and causal language-modeling losses. is BERT’s selected target set and
is BERT’s selected target set and  indexes one target token
indexes one target token  .
. denotes BERT’s visible corrupted context outside the selected targets, and
denotes BERT’s visible corrupted context outside the selected targets, and  is the reconstruction probability.
is the reconstruction probability. indexes a GPT target position,
indexes a GPT target position,  is sequence length, and
is sequence length, and  is the preceding token prefix.
is the preceding token prefix. is the next-token probability and
is the next-token probability and  converts each probability into a log-likelihood term.
converts each probability into a log-likelihood term.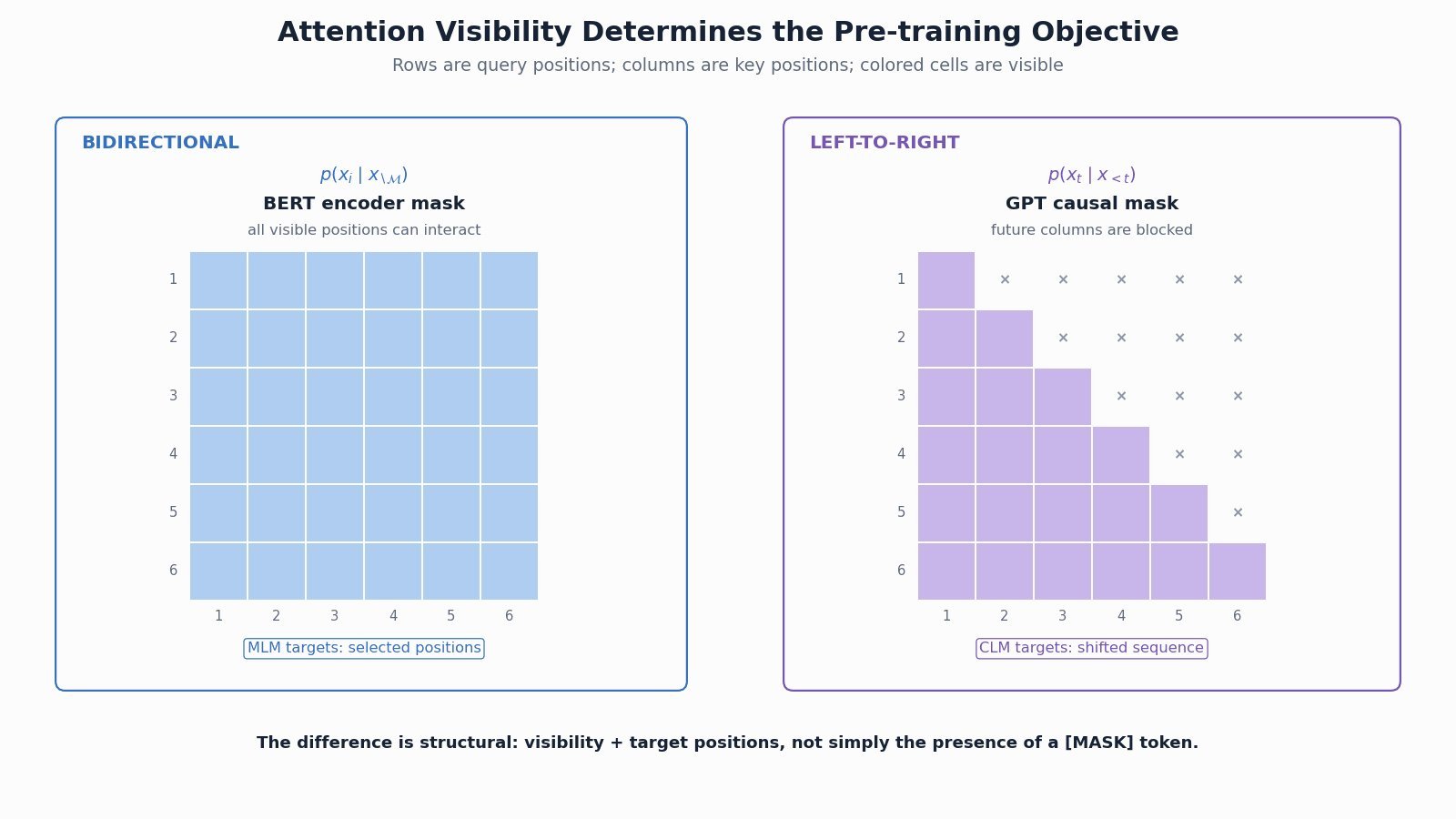
Figure 2: Attention visibility explains the objective difference: BERT uses a full visible-context matrix, while GPT uses a lower-triangular causal matrix.
 score and probability matrices in high-bandwidth memory (HBM), it loads blocks of
score and probability matrices in high-bandwidth memory (HBM), it loads blocks of  ,
,  , and
, and  into fast on-chip SRAM, computes attention block by block, and maintains online softmax statistics. Tiling reduces expensive HBM reads and writes, while recomputation during the backward pass can be cheaper than storing large intermediates. The mathematical result matches standard attention up to normal floating-point differences; the speedup comes from changing the execution schedule, not from approximating attention.
into fast on-chip SRAM, computes attention block by block, and maintains online softmax statistics. Tiling reduces expensive HBM reads and writes, while recomputation during the backward pass can be cheaper than storing large intermediates. The mathematical result matches standard attention up to normal floating-point differences; the speedup comes from changing the execution schedule, not from approximating attention.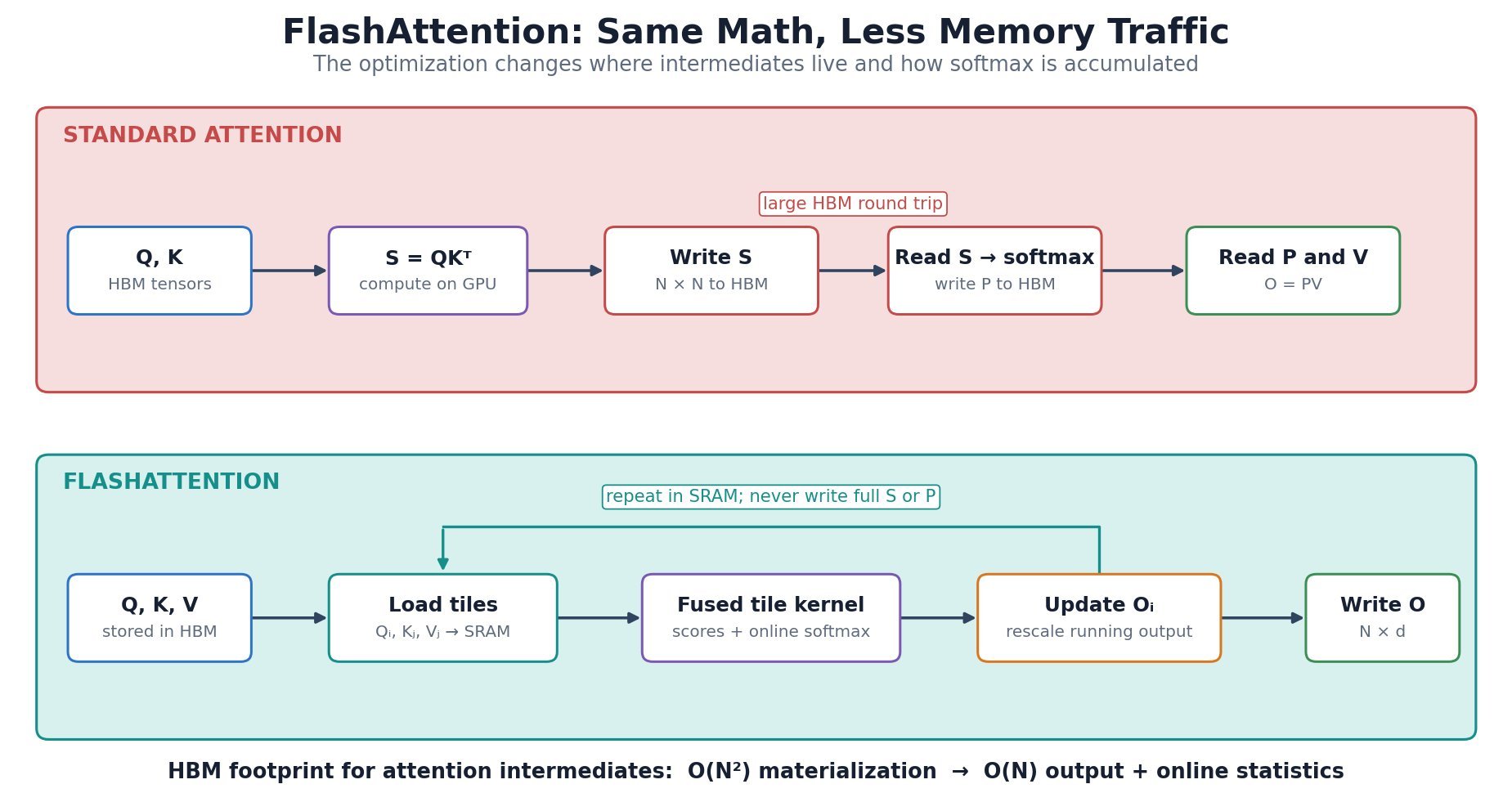
 tile to update the output without retaining previous score blocks.
tile to update the output without retaining previous score blocks.

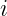 indexes a query row, and
indexes a query row, and  indexes keys inside tile
indexes keys inside tile  is the scaled score between query row
is the scaled score between query row  and key row
and key row  , with head width
, with head width  .
. is the running row maximum after tile
is the running row maximum after tile  .
. is the running softmax denominator, initialized with
is the running softmax denominator, initialized with  ; the exponential factors rescale earlier partial sums when the maximum changes.
; the exponential factors rescale earlier partial sums when the maximum changes.

 is the logit for token
is the logit for token  .
. is the hidden representation from the Transformer.
is the hidden representation from the Transformer.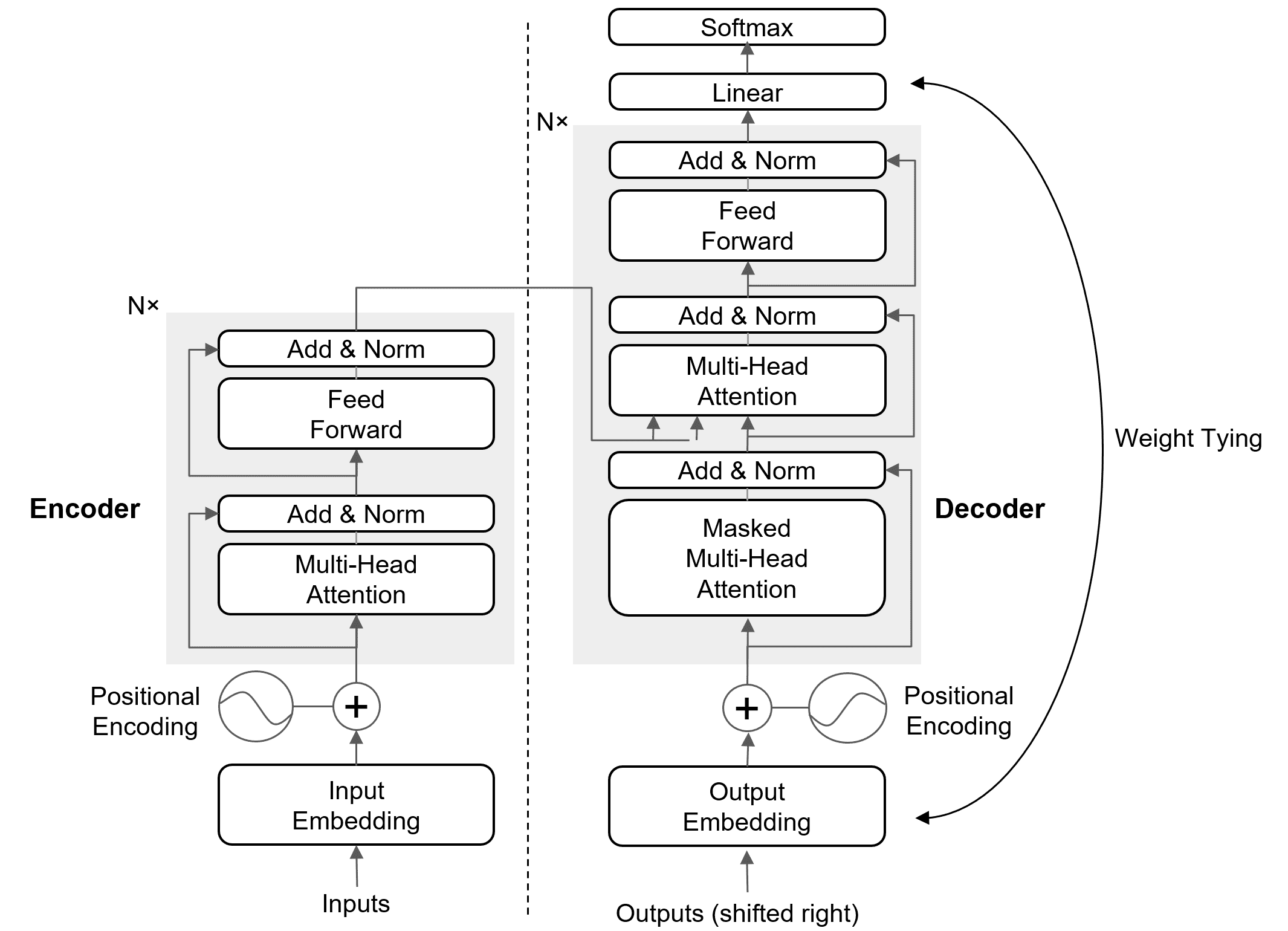
 ): Cost is relatively small; attention score matrix overhead is minimal. Q, K, and V projections together dominate the compute.
): Cost is relatively small; attention score matrix overhead is minimal. Q, K, and V projections together dominate the compute. 

 is large.
is large.