Explain weight sharing in Transformers.
Answer
Weight sharing in Transformers mainly refers to tying the input embedding matrix with the output projection matrix for softmax prediction, saving parameters, and improving consistency. In some models (like ALBERT), it also extends to sharing weights across Transformer layers for further parameter efficiency.
(1) Input–Output Embedding Tying:
The same embedding matrix is used for both input token embeddings and the output softmax projection.
Reduces parameters and enforces consistency between input and output spaces.
Where: is the logit for token
is the logit for token 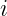 , computed using the embedding matrix
, computed using the embedding matrix  .
. is the hidden representation from the Transformer.
is the hidden representation from the Transformer. is the vocabulary size.
is the vocabulary size.
Weights tying are shown in the figure below.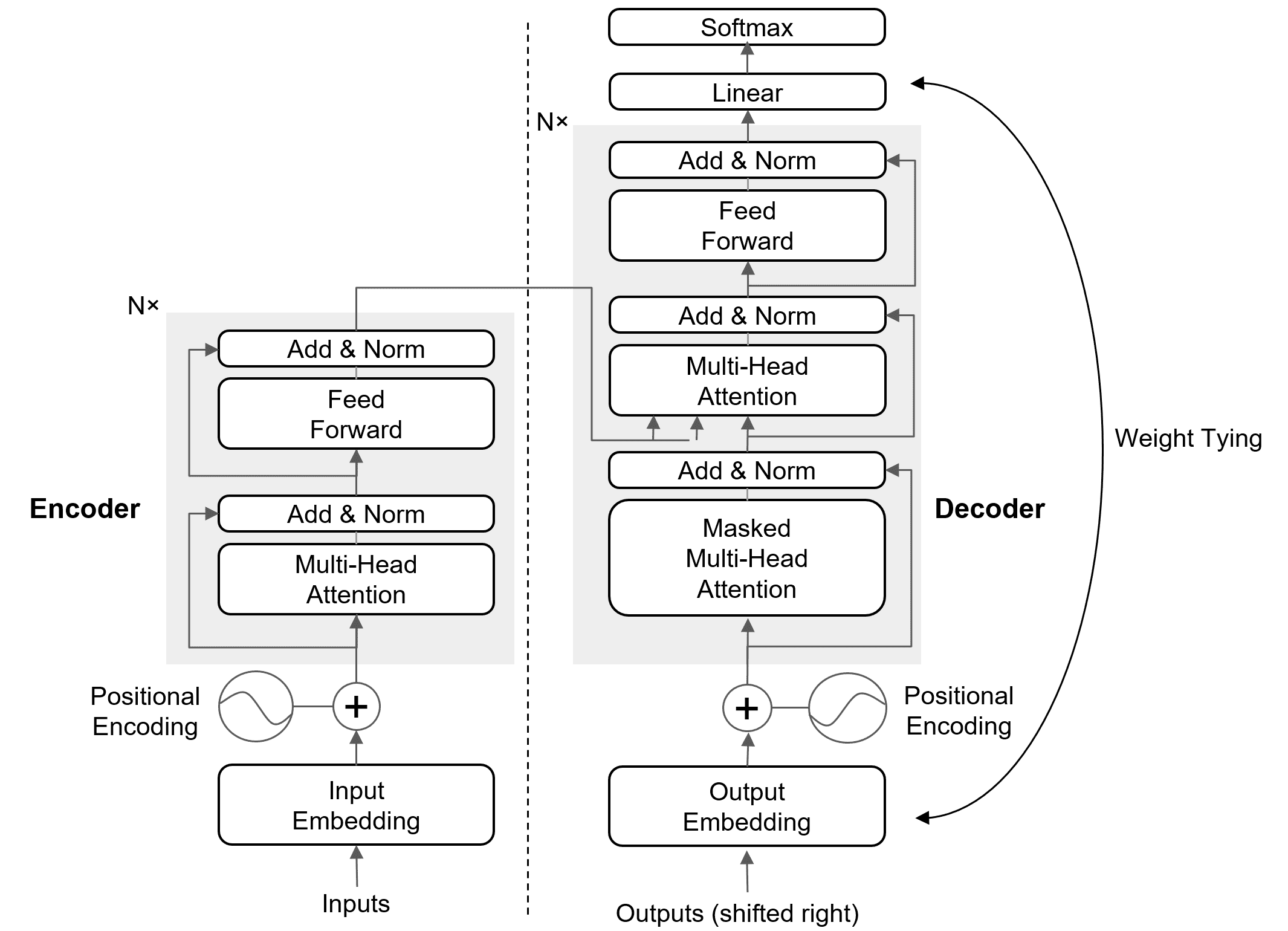
(2) Layer Weight Sharing (e.g., ALBERT [1]):
Instead of unique weights per layer, parameters are reused across all Transformer blocks.
Cuts model size dramatically while keeping depth.
References:
[1] Lan, Zhenzhong, et al. “Albert: A lite bert for self-supervised learning of language representations.” arXiv preprint arXiv:1909.11942 (2019).
Leave a Reply