In a Transformer architecture, which components are the primary contributors to computational cost, and why?
Answer
For short sequences, the feed-forward network (FFN) is often the dominant cost. For long sequences, the multi-head attention mechanism becomes the overwhelming bottleneck.
(1) Multi‑Head Attention (MHA):
Short sequences (small  ): Cost is relatively small; attention score matrix overhead is minimal. Q, K, and V projections together dominate the compute.
): Cost is relatively small; attention score matrix overhead is minimal. Q, K, and V projections together dominate the compute.
Long sequences (large ): Cost explodes quadratically with because every token attends to every other token. This becomes the main bottleneck. Cost: 
(2) Feed-Forward Network (FFN):
Two dense layers with an expansion factor of 4.
Cost: 
Short sequences: FFN dominates cost since is small, but  is large.
is large.
Long sequences: Cost grows linearly with , but MHSA cost overtakes it when is big.
The table below shows the FLOP breakdown comparing Multi‑Head Attention (MHA) and Feed‑Forward Network (FFN) at different sequence lengths for one of the transformer designs, where d=512.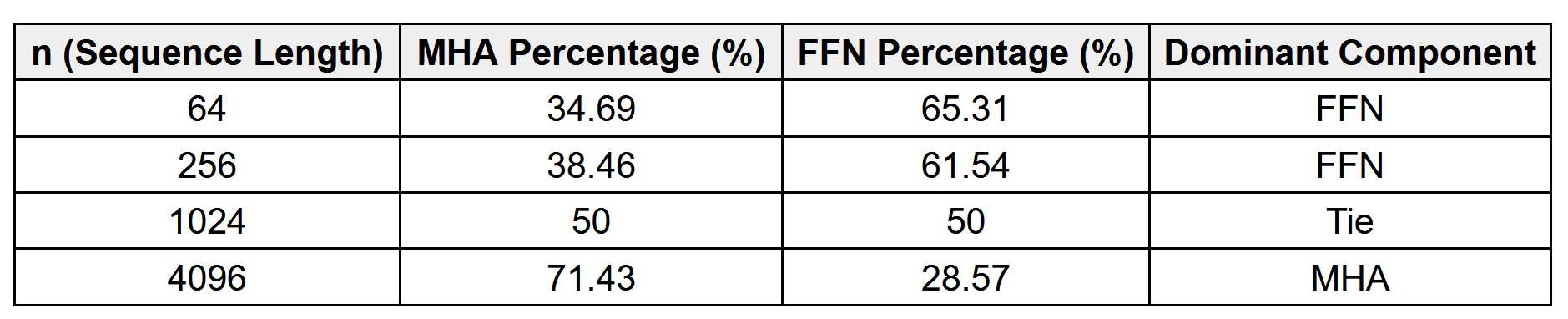
Leave a Reply