What is Rotary Positional Embedding (RoPE)?
Answer
Rotary Positional Embedding (RoPE) is a positional encoding method that rotates query and key vectors in multi‑head attention by position‑dependent angles. This rotation naturally encodes relative positional information, improves generalization to longer contexts, and avoids the limitations of fixed or learned absolute positional embeddings. It is used in GPT-NeoX, LLaMA, PaLM, Qwen, etc.
It has below charactretidstics:
(1) Relative position encoding method for Transformers
(2) Applies rotation to query (Q) and key (K) vectors using position-dependent angles
(3) Encodes position via geometry, not by adding vectors
(4) Preserves relative distance naturally in dot-product attention
(5) Extrapolates well to longer sequences than the training length
RoPE rotates each 2D pair of hidden dimensions:
Where:  represents the absolute position of the token in the sequence.
represents the absolute position of the token in the sequence.  represents the base frequency/rotation angle.
represents the base frequency/rotation angle.  represent the components of the embedding vector.
represent the components of the embedding vector.
The below plot visualizes how RoPE makes attention decay smoothly with relative distance, while standard sinusoidal PE reflects absolute position similarity.

 represents the i-th model weight
represents the i-th model weight controls the strength of sparsity
controls the strength of sparsity
 is the neuron input.
is the neuron input.
 to reveal more information about class similarities:
to reveal more information about class similarities:
 : Raw score (logit) for the i-th class.
: Raw score (logit) for the i-th class. : Total number of classes in the classification problem.
: Total number of classes in the classification problem. : Temperature parameter (>0) used to soften the probabilities. Higher
: Temperature parameter (>0) used to soften the probabilities. Higher 

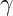 to suppress easy-example gradients and focus learning on hard examples, making it preferable when many easy negatives overwhelm training but requiring careful tuning to avoid amplifying label noise.
to suppress easy-example gradients and focus learning on hard examples, making it preferable when many easy negatives overwhelm training but requiring careful tuning to avoid amplifying label noise.
 is the model probability for the ground-truth class;
is the model probability for the ground-truth class; is the per-class weight for class t.
is the per-class weight for class t.
 is the focusing parameter that down-weights easy examples.
is the focusing parameter that down-weights easy examples.

 →
→  ) before reducing it back?
) before reducing it back? ) to enhance the model’s ability to learn complex, non-linear feature interactions, then reduces it back to maintain compatibility with other layers. This design acts as a bottleneck, balancing expressiveness and efficiency, and has been empirically shown to boost performance in large-scale models.
) to enhance the model’s ability to learn complex, non-linear feature interactions, then reduces it back to maintain compatibility with other layers. This design acts as a bottleneck, balancing expressiveness and efficiency, and has been empirically shown to boost performance in large-scale models. allows the FFN to capture richer nonlinear transformations.
allows the FFN to capture richer nonlinear transformations.
 is the input vector.
is the input vector. expands the dimension.
expands the dimension. is a non-linear activation (e.g., ReLU/GELU).
is a non-linear activation (e.g., ReLU/GELU). projects back down.
projects back down.


 represents the query vector for the ith attention head.
represents the query vector for the ith attention head. and
and  represent the single, shared key and value vectors used by all heads.
represent the single, shared key and value vectors used by all heads. is the dimension of the key vectors.
is the dimension of the key vectors.
 , hidden dimension =
, hidden dimension =  , number of heads =
, number of heads =  .
. is projected into queries, keys, and values.
is projected into queries, keys, and values. (for all 3 matrices).
(for all 3 matrices).




 = raw score for position
= raw score for position 

 applied to values
applied to values  :
:


 , the dominant term is:
, the dominant term is: .
.
 and key
and key  grows larger when they point in similar directions, making it a natural similarity measure.
grows larger when they point in similar directions, making it a natural similarity measure.
 is the dot product similarity between query and key.
is the dot product similarity between query and key.
 , which is hardware-friendly.
, which is hardware-friendly. to a lower bound depending on the sparsity pattern.
to a lower bound depending on the sparsity pattern.
 are the dilated subsets of keys and values.
are the dilated subsets of keys and values.