Why do Transformers use a dot product, rather than addition, to compute attention scores?
Answer
Dot product attention is a fast and naturally aligned similarity measure; with scaling, it remains numerically stable and highly parallelizable, which is why Transformers prefer it over addition.
(1) Dot product captures similarity: The dot product between query  and key
and key  grows larger when they point in similar directions, making it a natural similarity measure.
grows larger when they point in similar directions, making it a natural similarity measure.
The scores are normalized with Softmax and have probabilistic interpretations:
Where: is the dot product similarity between query and key.
is the dot product similarity between query and key.
The figure below illustrates the dot product for measuring similarity.
(2) Efficient computation: Dot products can be computed in parallel as a matrix multiplication  , which is hardware-friendly.
, which is hardware-friendly.
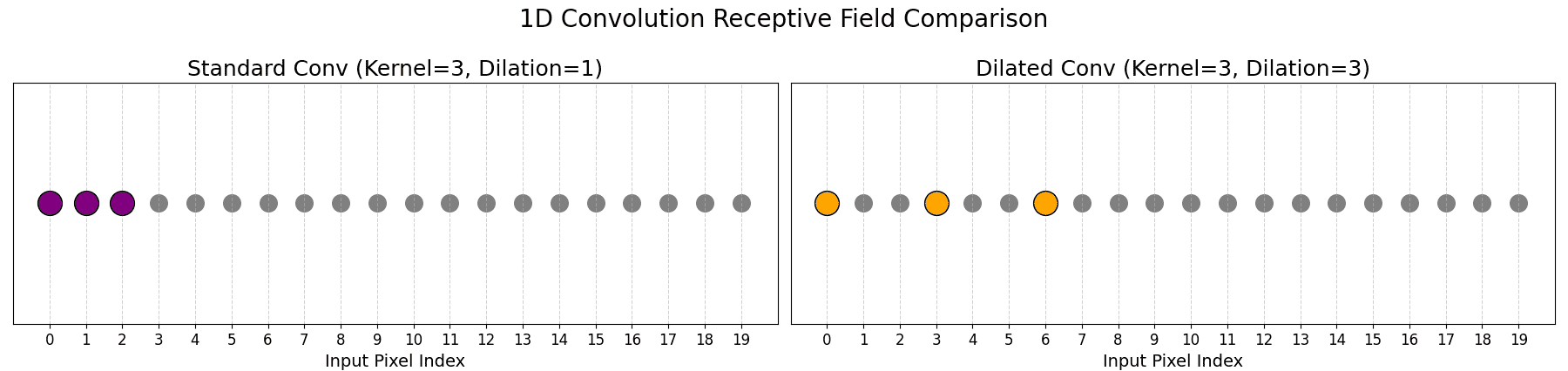
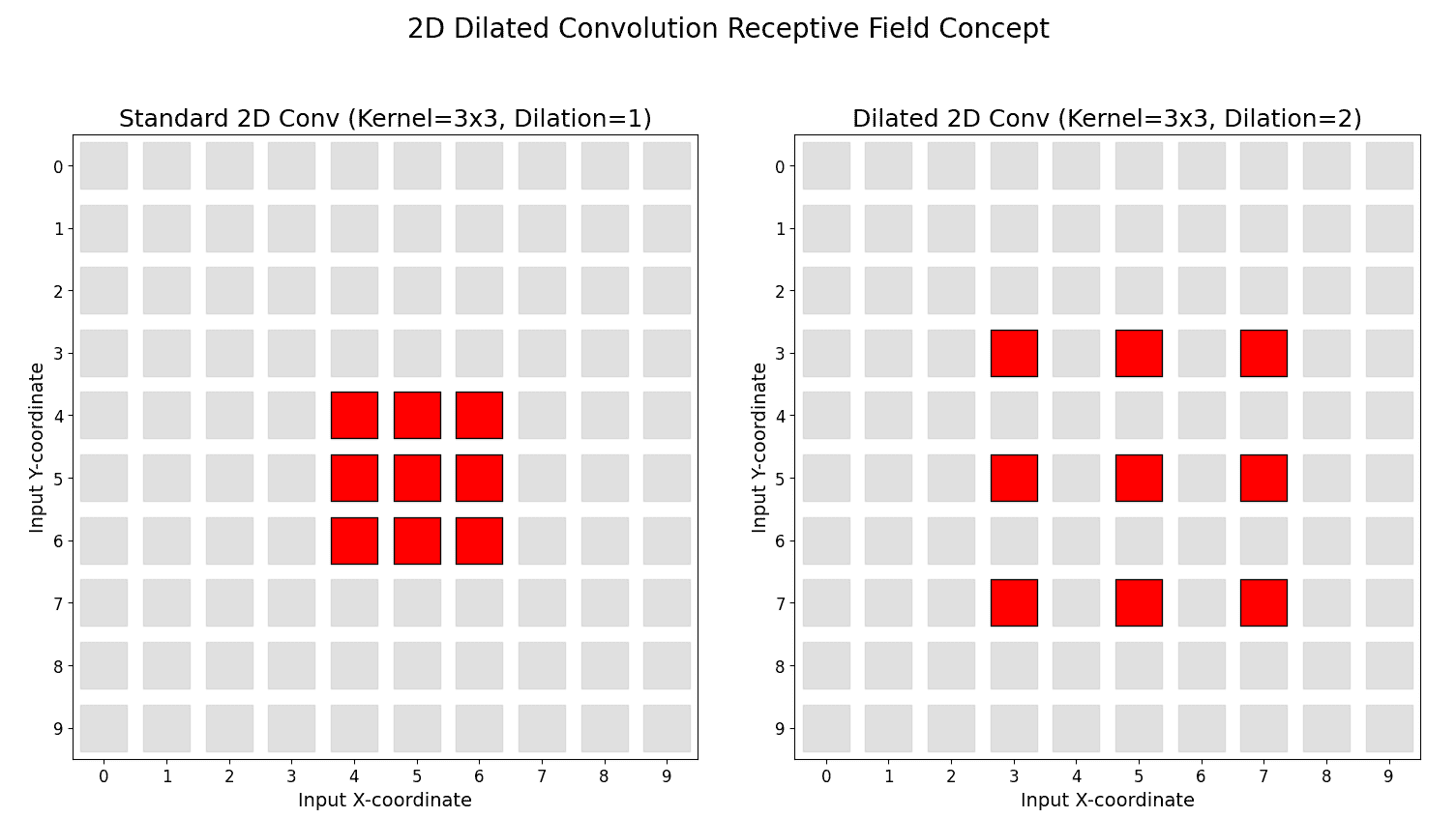
 to a lower bound depending on the sparsity pattern.
to a lower bound depending on the sparsity pattern.
 are the dilated subsets of keys and values.
are the dilated subsets of keys and values. is the key dimension.
is the key dimension.
 (e.g., the token itself and
(e.g., the token itself and  neighbors).
neighbors). .
.


 for input
for input  :
:



 , channel
, channel  , height
, height  , and width
, and width  is the height of the feature map (number of rows per channel).
is the height of the feature map (number of rows per channel). is the width of the feature map (number of columns per channel).
is the width of the feature map (number of columns per channel). is the mean of all spatial values in channel
is the mean of all spatial values in channel  is the variance of spatial values in channel
is the variance of spatial values in channel  is the normalized value after subtracting the mean and dividing by the standard deviation.
is the normalized value after subtracting the mean and dividing by the standard deviation. is a small constant added to the denominator to prevent division by zero and improve numerical stability.
is a small constant added to the denominator to prevent division by zero and improve numerical stability. is a learnable scale parameter for channel
is a learnable scale parameter for channel  is a learnable shift parameter for channel
is a learnable shift parameter for channel