What are the two main distributed training approaches for machine learning?
Answer
The two main distributed training approaches for machine learning are Data Parallelism and Model Parallelism.
Data Parallelism: In this approach, the training dataset is divided and distributed among multiple computing devices, with each device holding a complete copy of the machine learning model. Each device then trains its model on its assigned subset of the data in parallel. After each training step, the updates (gradients or new parameters) from all devices are aggregated and synchronized to maintain a consistent model across the system. This method is highly effective for scaling training when the dataset is large and the model can fit within a single device’s memory.
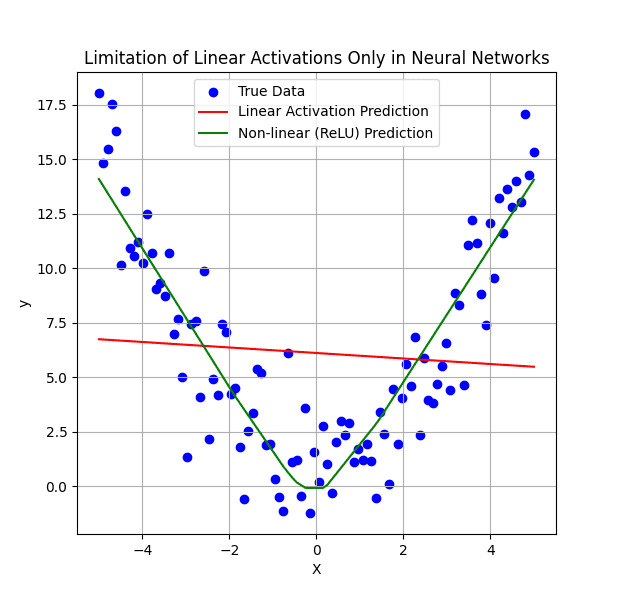
Model Parallelism: This approach is used when the machine learning model itself is too large to fit into the memory of a single computing device. In model parallelism, different parts of the model (e.g., specific layers of a neural network) are distributed across multiple devices. Data typically flows sequentially through these distributed model parts. This necessitates more complex communication between devices as intermediate computations and activations must be passed along. Model parallelism is crucial for training extremely large models that would otherwise be computationally intractable on a single machine.


 (its activation) and a weighted sum
(its activation) and a weighted sum  computed as:
computed as:

 is the target value.
is the target value. 


 that feeds into the output neurons. Its contribution to the loss is influenced by all neurons it connects to in the subsequent layer. The backpropagated error for neuron
that feeds into the output neurons. Its contribution to the loss is influenced by all neurons it connects to in the subsequent layer. The backpropagated error for neuron 
 is the derivative of the activation function at neuron
is the derivative of the activation function at neuron  for a neuron, the gradient with respect to a weight
for a neuron, the gradient with respect to a weight  connected to input
connected to input  is:
is:


 represents the hypothesis (predicted value) for input feature vector x.
represents the hypothesis (predicted value) for input feature vector x. is the bias (intercept) parameter, shifting the prediction up or down independent of features.
is the bias (intercept) parameter, shifting the prediction up or down independent of features. are the weight parameters multiplying each feature.
are the weight parameters multiplying each feature. denotes the j‑th feature of the input vector x.
denotes the j‑th feature of the input vector x.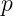 is the total number of features (excluding the bias) used in the model.
is the total number of features (excluding the bias) used in the model.

 represents the raw score (also known as a “logit”) for the i th class.
represents the raw score (also known as a “logit”) for the i th class.  represents the total number of classes in the classification problem.
represents the total number of classes in the classification problem.