Please compare focal loss and weighted cross-entropy.
Answer
Weighted Cross-Entropy (WCE) rescales loss by class to correct prior imbalance and is simple and robust for noisy labels; Focal Loss (FL) multiplies cross-entropy by a difficulty-dependent factor 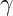 to suppress easy-example gradients and focus learning on hard examples, making it preferable when many easy negatives overwhelm training but requiring careful tuning to avoid amplifying label noise.
to suppress easy-example gradients and focus learning on hard examples, making it preferable when many easy negatives overwhelm training but requiring careful tuning to avoid amplifying label noise.

Where: is the model probability for the ground-truth class;
is the model probability for the ground-truth class; is the per-class weight for class t.
is the per-class weight for class t.

Where: is the model probability for the ground-truth class; is the optional per-class weight for class t; is the focusing parameter that down-weights easy examples.
is the focusing parameter that down-weights easy examples.
Here is a table to compare focal loss and weighted cross-entropy.
The figure below compares Cross-Entropy, Weighted Cross-Entropy, and Focal Loss.
 and an optional balancing weight
and an optional balancing weight  is an optional class-balancing weight for class t.
is an optional class-balancing weight for class t.
 .
.

 is the true label,
is the true label, is the raw model output.
is the raw model output.
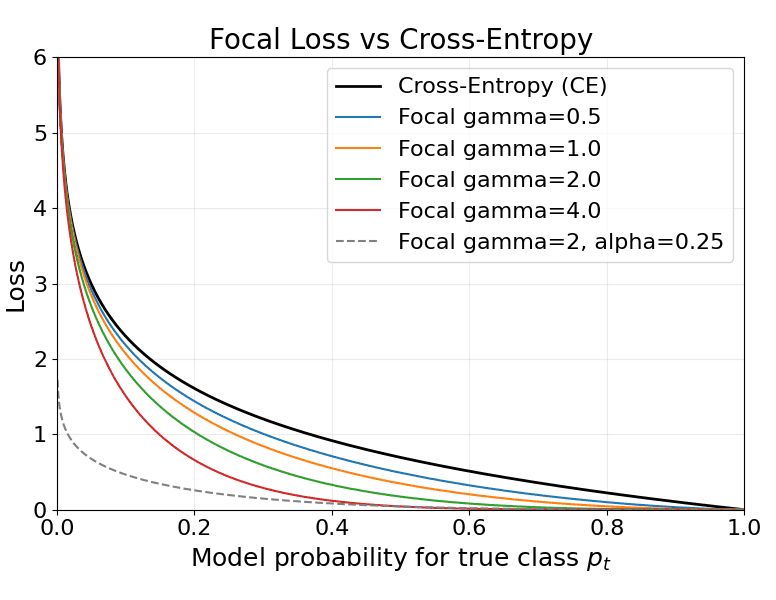
 , meaning the point is correctly classified with margin.
, meaning the point is correctly classified with margin. , the point is either inside the margin or misclassified.
, the point is either inside the margin or misclassified.
![{\large \text{Binary Cross-Entropy Loss} = - \displaystyle\frac{1}{n}\sum_{i=1}^{n} [y_i \cdot \log(p_i) + (1-y_i) \cdot \log(1-p_i)]}](https://s0.wp.com/latex.php?latex=%7B%5Clarge+%5Ctext%7BBinary+Cross-Entropy+Loss%7D+%3D+-+%5Cdisplaystyle%5Cfrac%7B1%7D%7Bn%7D%5Csum_%7Bi%3D1%7D%5E%7Bn%7D+%5By_i+%5Ccdot+%5Clog%28p_i%29+%2B+%281-y_i%29+%5Ccdot+%5Clog%281-p_i%29%5D%7D&bg=ffffff&fg=000&s=0&c=20201002)
 is the number of total samples.
is the number of total samples. is the true label (0 or 1) for the i-th data point.
is the true label (0 or 1) for the i-th data point. is the predicted probability of the positive class (class 1) for the i-th data point.
is the predicted probability of the positive class (class 1) for the i-th data point.
 is the number of classes.
is the number of classes. is a binary indicator (0 or 1) that is 1 if the true class for the i-th data point is j, and 0 otherwise (one-hot encoding).
is a binary indicator (0 or 1) that is 1 if the true class for the i-th data point is j, and 0 otherwise (one-hot encoding). is the predicted probability that the i-th data point belongs to class j.
is the predicted probability that the i-th data point belongs to class j.
 represents the predicted value for the i-th data point.
represents the predicted value for the i-th data point.