Explain the Hinge Loss function used in SVM.
Answer
The Hinge Loss function is a key element in Support Vector Machines that penalizes both misclassified points and correctly classified points that lie within the decision margin. It assigns zero loss to points that are correctly classified and lie outside or exactly on the margin, and applies a linearly increasing loss as points move closer to or across the decision boundary. This loss structure encourages the SVM to maximize the margin between classes, promoting robust and generalizable decision boundaries.
The Hinge Loss is defined as follows.
Where: is the true label,
is the true label, is the raw model output.
is the raw model output.
Hinge Loss is plotted in the figure below.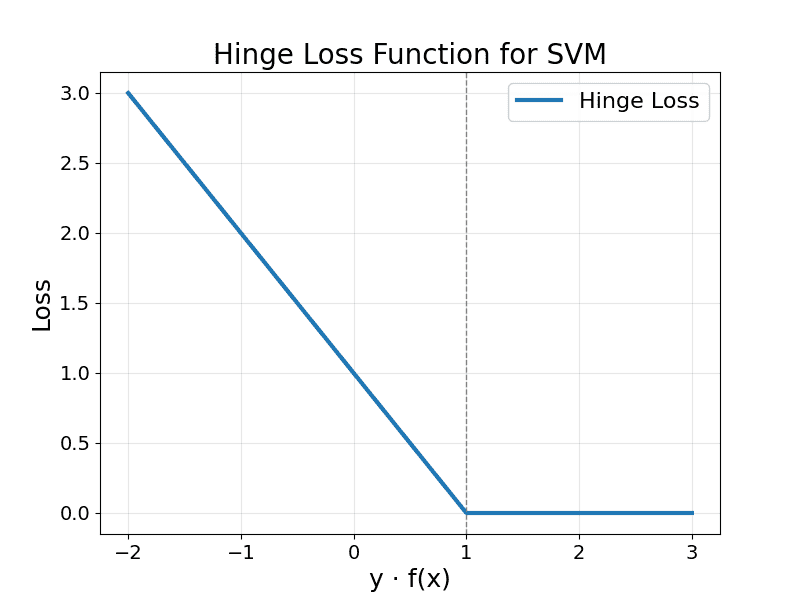
Zero Loss: When  , meaning the point is correctly classified with margin.
, meaning the point is correctly classified with margin.
Positive Loss: When  , the point is either inside the margin or misclassified.
, the point is either inside the margin or misclassified.

 are input vectors.
are input vectors. controls the scale of the inner product.
controls the scale of the inner product. is a constant that controls the influence of higher-order terms.
is a constant that controls the influence of higher-order terms. is the degree of the polynomial.
is the degree of the polynomial.
 is the squared Euclidean distance between the vectors.
is the squared Euclidean distance between the vectors. is a parameter that controls the width of the Gaussian (spread).
is a parameter that controls the width of the Gaussian (spread).
 is a bias term.
is a bias term.
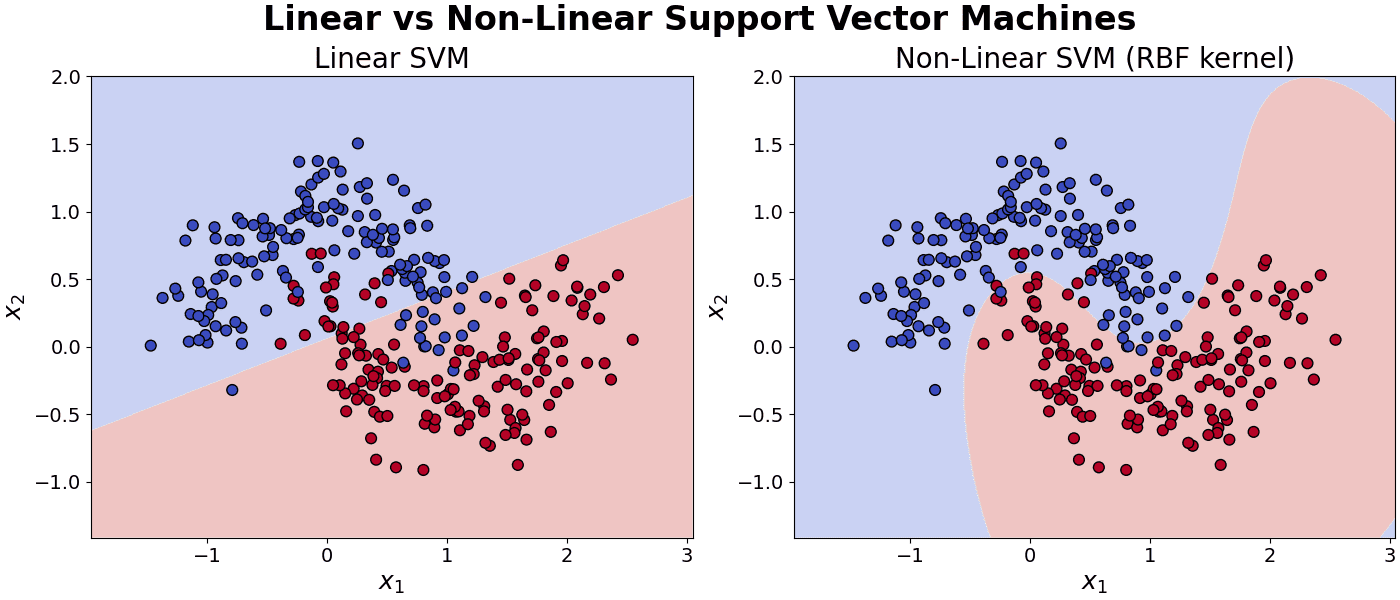

 is the input feature vector.
is the input feature vector. is the weight vector.
is the weight vector. is the bias term.
is the bias term.
 is the predicted class label.
is the predicted class label. returns +1 if the argument is ≥ 0, and −1 otherwise.
returns +1 if the argument is ≥ 0, and −1 otherwise.

 is the class label for the i-th data point.
is the class label for the i-th data point. is the i-th feature vector.
is the i-th feature vector.