What are the potential consequences of initializing all weights to one in a deep learning model?
Answer
Below are the key consequences of initializing all weights in a deep-learning model to one (a constant non-zero value), illustrating why random, scaled initializations (e.g., Xavier/He) are essential. (1) Symmetry Problem: Neurons receive identical gradients, causing them to learn the same features rather than developing distinct representations. (2) Limited Representational Capacity: The network cannot capture complex, varied patterns because all neurons behave identically. (3) Slow/No Convergence: The lack of Representational Capacity further makes it difficult for the model to update to the optimal weights. (The below image shows an example for training loss comparison for ones initialization vs random initialization) (4) Activation Saturation: Can push neurons into saturated regions of activation functions (e.g., sigmoid, tanh), leading to vanishing gradients.
Why are residual connections important in deep neural networks?
Answer
A residual connection (skip connection) adds a block input to a learned residual transformation, so the block learns an update rather than an entirely new mapping. For a shape-preserving block, the local Jacobian becomes , which supplies a direct identity component and creates shorter paths through the computational graph. This usually improves gradient propagation and optimization, but it does not guarantee nonzero or constant gradients: products of residual-block Jacobians can still shrink, grow, or cancel. Residual connections also address the degradation problem, in which adding layers to a plain network can increase training error because the deeper model is difficult to optimize even though an identity extension exists. These properties enabled effective training of ResNet architectures with hundreds of layers.
Figure 1: A shape-preserving block uses an identity shortcut, while a block that changes resolution or channel width uses a learned projection so the two paths have compatible shapes.
(1) Shorter Gradient Paths: An identity shortcut changes the local block Jacobian from to . The identity component gives backpropagation additional routes, although the product across many blocks can still vanish or explode.
(2) Identity Mapping Fallback: When an additional shape-preserving block is not useful, its residual branch can approach zero, making easier to represent than in a plain nonlinear stack.
(3) Easier Deep Optimization: Residual parameterization helps deeper models avoid the degradation problem, where added layers increase training error because optimization fails to recover a useful identity extension.
Mathematical Formulation:
Where:
is the input to residual block , and is its output.
is the learned residual branch parameterized by weights ; it learns an update to the shortcut representation.
is the residual-branch Jacobian, and is the identity operator with the same feature dimension as .
is an identity operator when input and output shapes match; otherwise it can be a learned projection, such as a strided convolution, that aligns spatial and channel dimensions.
Across residual blocks, backpropagation contains products of factors . These factors often improve conditioning relative to plain Jacobian products, but they do not impose a nonzero lower bound on gradient magnitude.
Figure 2: A plain stack multiplies full layer Jacobians, whereas a residual stack multiplies factors . The identity components provide additional gradient routes but do not guarantee stable magnitude.
What are the advantages and disadvantages of linear regression?
Answer
Linear regression aims to model the relationship between a dependent variable and one or more independent variables by fitting a linear equation to observed data.
Where represents the hypothesis (predicted value) for input feature vector x. is the bias (intercept) parameter, shifting the prediction up or down independent of features. are the weight parameters multiplying each feature. denotes the j‑th feature of the input vector x. is the total number of features (excluding the bias) used in the model.
Advantages: (1) Simplicity & Interpretability: Linear regression is easy to understand and implement. The coefficients of the model directly indicate the strength and direction of the relationship between the features and the target variable, making it highly interpretable. (2) Computational Efficiency: Its low computational cost makes linear regression fast to train, even on large datasets. (3) Effective for Linearly Separable Data: It performs well when the relationship between the independent and dependent variables is approximately linear.
Disadvantages: (1) Assumes Linearity: The primary limitation is the assumption that the relationship between the variables is linear. It will perform poorly if the underlying relationship is nonlinear. (2) Sensitivity to Outliers: Extreme values can disproportionately affect the model, distorting the results. (3) Multicollinearity Issues: When predictors are highly correlated, it becomes difficult to isolate individual effects, leading to unreliable coefficient estimates (4) Potential for Underfitting: The simplicity of the model may fail to capture the nuances and complexities of more intricate datasets.
What are the advantages and disadvantages of using a sigmoid activation function?
Answer
The sigmoid activation function transforms input values into a range between 0 and 1, making it useful in various applications like binary classification.
Advantages: (1) Smooth, Bounded Gradient: The sigmoid’s S‑shape yields a continuous derivative, preventing abrupt changes in backpropagation and aiding stable training on shallow networks. (2) Probability interpretation: Since the output is between 0 and 1, it can be useful for problems where predictions need to represent probabilities.
Disadvantages: (1) Vanishing gradient problem: For very large or small inputs, the gradient becomes almost zero, slowing down training in deep networks. (2) Not zero-centered: The outputs are always positive, which can lead to inefficient weight updates and slower convergence.
What are the advantages and disadvantages of using the tanh activation function?
Answer
In machine learning, the hyperbolic tangent (tanh) activation function is defined as This function transforms input values into a range between -1 and 1, helping with faster convergence in neural networks.
Advantages: (1) Zero-centered outputs: Unlike sigmoid, which outputs values between 0 and 1, tanh produces values between -1 and 1, making optimization easier and reducing bias in gradient updates. (2) Smooth and Differentiable: The function is infinitely differentiable, supporting stable gradient‑based methods.
Disadvantages: (1) Vanishing gradient problem: For very large or very small input values, the derivative of tanh approaches zero, leading to slow weight updates and potentially hindering deep network training. (2) Computationally expensive: Compared to ReLU, tanh requires exponentially complex calculations, which may slow down model inference.
What is the Softmax activation function, and what is its purpose?
Answer
Softmax is an activation function typically used in the output layer of a neural network for multi-class classification problems. Its purpose is to convert a vector of raw scores (logits) into a probability distribution over the possible output classes. The output of Softmax is a vector where each element represents the probability of the input belonging to a specific class, and the sum of these probabilities is always 1. Where: represents the raw score (also known as a “logit”) for the i th class. represents the total number of classes in the classification problem.
The combination of the softmax function with the cross-entropy loss function is standard for multi-class classification problems. The softmax function provides a probability distribution over classes, and the cross-entropy loss measures how well this predicted distribution aligns with the true distribution (typically a one-hot encoded vector).
What are the benefits of the Leaky ReLU activation function?
Answer
Leaky ReLU modifies the standard ReLU by allowing a small, non-zero gradient for negative inputs. Its formula is typically written as:
Advantages of Leaky ReLU: 1. Addresses the dying ReLU problem: By having a small non-zero slope for negative inputs, Leaky ReLU allows a small gradient to flow even when the neuron is not active in the positive region. This prevents neurons from getting stuck in a permanently inactive state and potentially helps them recover during training. 2. Retains the benefits of ReLU for positive inputs: Maintains the linearity and non-saturation for positive values, contributing to efficient computation and gradient propagation.
What are the benefits and limitations of the ReLU activation function?
Answer
ReLU offers substantial benefits in terms of computational efficiency, gradient propagation, and sparsity, which have made it a popular choice for activation functions in deep learning.
Advantages of ReLU: 1. Mitigation of the Vanishing Gradient Problem: In the positive region (x>0), ReLU has a constant gradient of 1. This helps to alleviate the vanishing gradient problem that plagues sigmoid and tanh functions, especially in deep networks. A constant gradient allows for more effective backpropagation of the error signal to earlier layers. 2. Sparse Activation: By outputting zero for all negative input values, ReLU naturally induces sparsity in the network. This means that, at any given time, only a subset of neurons are active. Sparse activations can lead to more efficient representations and can help the network learn more robust features. 3. Computational Efficiency: ReLU is computationally simple, requiring only a threshold operation, which accelerates both training and inference processes compared to functions like sigmoid or tanh that involve more complex calculations.
Drawbacks of ReLU: 1. Dying ReLU Problem: Neurons can become inactive if they consistently receive negative inputs, leading them to output zero and potentially never recover, thus reducing the model’s capacity. 2. Unbounded Output: The unbounded nature of ReLU’s positive outputs can lead to large activation values, potentially causing issues like exploding gradients if not properly managed.
What are the typical reasons for exploding gradient?
Answer
Exploding gradients occur when the gradients during backpropagation become excessively large. This leads to huge updates in the model’s weights, making the training process unstable and potentially causing the model to diverge instead of converging.
Typical Reasons for Exploding Gradients: 1. Deep Architectures: In very deep networks, repeatedly multiplying gradients (especially when derivatives are >1) can cause them to grow exponentially
2. Large Learning Rates: When the learning rate is set too high, even moderately large gradients can result in weight updates that overshoot the optimum by a significant margin, compounding the instability.
3. Improper Weight Initialization: If weights are initialized to values that are too high, activations and their corresponding derivatives can be disproportionately large. This imbalance not only disrupts the symmetry in learning but can also contribute to the accumulation of large gradient values.
4. Activation Functions with Derivatives Greater Than 1: Some activation functions or their operating regimes can have derivatives greater than 1. Repeated multiplication of these large derivatives during backpropagation can lead to exponential growth of the gradients. Scaled Exponential Linear Unit (SELU). For positive inputs, the SELU is defined as: In the typical configuration for self-normalizing neural networks, the parameter is set to approximately 1.0507 (greater than 1). This means in the positive regime, each layer effectively amplifies the gradient by a factor of , which, when compounded over many layers, can contribute to exploding gradients if not properly managed.
What are the typical reasons for vanishing gradient?
Answer
The vanishing gradient problem occurs during the training of deep neural networks when gradients become exceedingly small as they are backpropagated through the network’s layers. This diminishes the effectiveness of weight updates, particularly in the earlier layers, hindering the network’s ability to learn and converge efficiently.
Typical Reasons for Vanishing Gradients: 1. Saturating Activation Functions: Activation functions, such as the sigmoid or tanh, compress input values into a narrow range. For example, the sigmoid function is defined as: Its derivative is: Notice that when has very high or very low values, saturates close to 1 or 0, making extremely small. When such small derivatives are multiplied across many layers (as dictated by the chain rule), they shrink toward zero, leading to vanishing gradients.
2. Deep Network Architectures: In deep models, the gradient for a given layer involves a product of many small derivatives from subsequent layers. Mathematically, if you consider a simple scenario, the gradient with respect to an early layer might be expressed as: If each term in the product is less than one in absolute value, the overall product becomes extremely small as n (the number of layers) increases.
3. Improper Weight Initialization: The way weights are initialized can have a significant impact on the magnitude of the gradients. If the initial weights are set too small (or too large), they can push the activations into the non-linear saturation regions of functions like the sigmoid or tanh, causing their derivatives to be very small. This, in turn, contributes to vanishing gradients.
4. Recurrent Neural Networks (RNNs): RNNs are particularly susceptible because the gradients must pass through many time steps (or iterations) when backpropagating through time. Similar to deep feedforward networks, if the gradient at each time step is less than one, the multiplicative effect causes the overall gradient to vanish over long sequences

 , which supplies a direct identity component and creates shorter paths through the computational graph. This usually improves gradient propagation and optimization, but it does not guarantee nonzero or constant gradients: products of residual-block Jacobians can still shrink, grow, or cancel. Residual connections also address the degradation problem, in which adding layers to a plain network can increase training error because the deeper model is difficult to optimize even though an identity extension exists. These properties enabled effective training of ResNet architectures with hundreds of layers.
, which supplies a direct identity component and creates shorter paths through the computational graph. This usually improves gradient propagation and optimization, but it does not guarantee nonzero or constant gradients: products of residual-block Jacobians can still shrink, grow, or cancel. Residual connections also address the degradation problem, in which adding layers to a plain network can increase training error because the deeper model is difficult to optimize even though an identity extension exists. These properties enabled effective training of ResNet architectures with hundreds of layers.
 so the two paths have compatible shapes.
so the two paths have compatible shapes. to
to  can approach zero, making
can approach zero, making  easier to represent than in a plain nonlinear stack.
easier to represent than in a plain nonlinear stack.


 is the input to residual block
is the input to residual block  , and
, and  is its output.
is its output. is the learned residual branch parameterized by weights
is the learned residual branch parameterized by weights  ; it learns an update to the shortcut representation.
; it learns an update to the shortcut representation. is the residual-branch Jacobian, and
is the residual-branch Jacobian, and  is the identity operator with the same feature dimension as
is the identity operator with the same feature dimension as  convolution, that aligns spatial and channel dimensions.
convolution, that aligns spatial and channel dimensions. residual blocks, backpropagation contains products of factors
residual blocks, backpropagation contains products of factors  . These factors often improve conditioning relative to plain Jacobian products, but they do not impose a nonzero lower bound on gradient magnitude.
. These factors often improve conditioning relative to plain Jacobian products, but they do not impose a nonzero lower bound on gradient magnitude.

 represents the hypothesis (predicted value) for input feature vector x.
represents the hypothesis (predicted value) for input feature vector x. is the bias (intercept) parameter, shifting the prediction up or down independent of features.
is the bias (intercept) parameter, shifting the prediction up or down independent of features. are the weight parameters multiplying each feature.
are the weight parameters multiplying each feature. denotes the j‑th feature of the input vector x.
denotes the j‑th feature of the input vector x.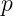 is the total number of features (excluding the bias) used in the model.
is the total number of features (excluding the bias) used in the model.


 represents the raw score (also known as a “logit”) for the i th class.
represents the raw score (also known as a “logit”) for the i th class.  represents the total number of classes in the classification problem.
represents the total number of classes in the classification problem.


 is set to approximately 1.0507 (greater than 1). This means in the positive regime, each layer effectively amplifies the gradient by a factor of
is set to approximately 1.0507 (greater than 1). This means in the positive regime, each layer effectively amplifies the gradient by a factor of 

 has very high or very low values,
has very high or very low values,  saturates close to 1 or 0, making
saturates close to 1 or 0, making  extremely small. When such small derivatives are multiplied across many layers (as dictated by the chain rule), they shrink toward zero, leading to vanishing gradients.
extremely small. When such small derivatives are multiplied across many layers (as dictated by the chain rule), they shrink toward zero, leading to vanishing gradients.