Why is zero padding used in deep learning?
Answer
Zero padding in deep learning, particularly in CNNs, is a technique of adding layers of zeros around the input to convolutional layers. This is crucial for maintaining the spatial dimensions of feature maps, preventing loss of information at the image or feature map borders, enabling the use of larger receptive fields via larger kernels, and providing control over the output size of convolutional operations. Ultimately, it helps in building deeper and more effective neural networks by preserving important spatial information throughout the network.
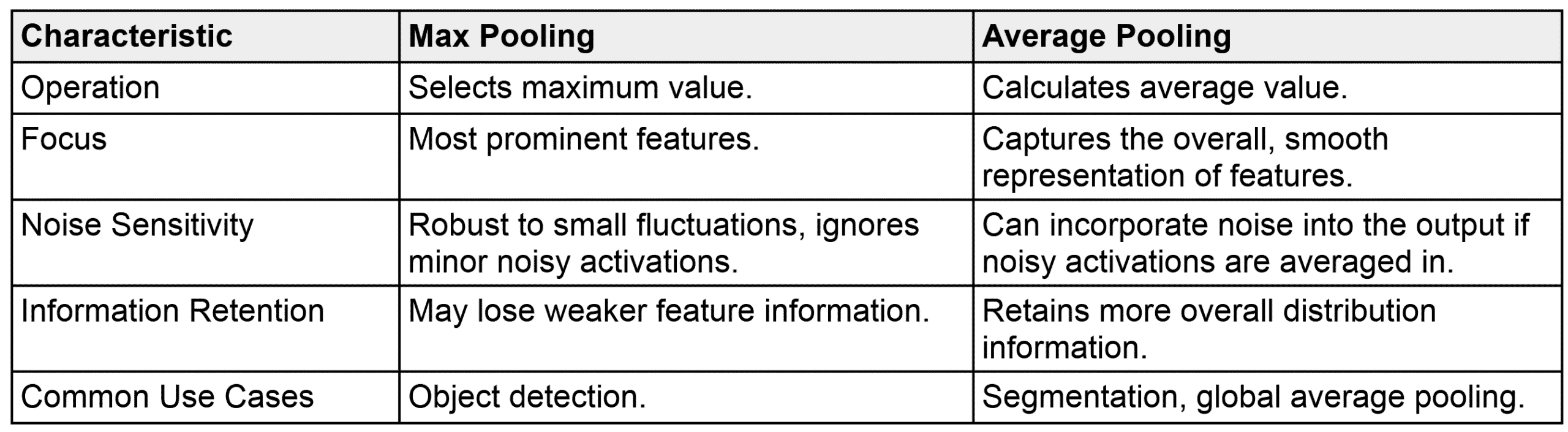
Here are the benefits of using zero padding for CNN.
(1) Preserves Spatial Dimensions: Prevents feature maps from shrinking after convolution.
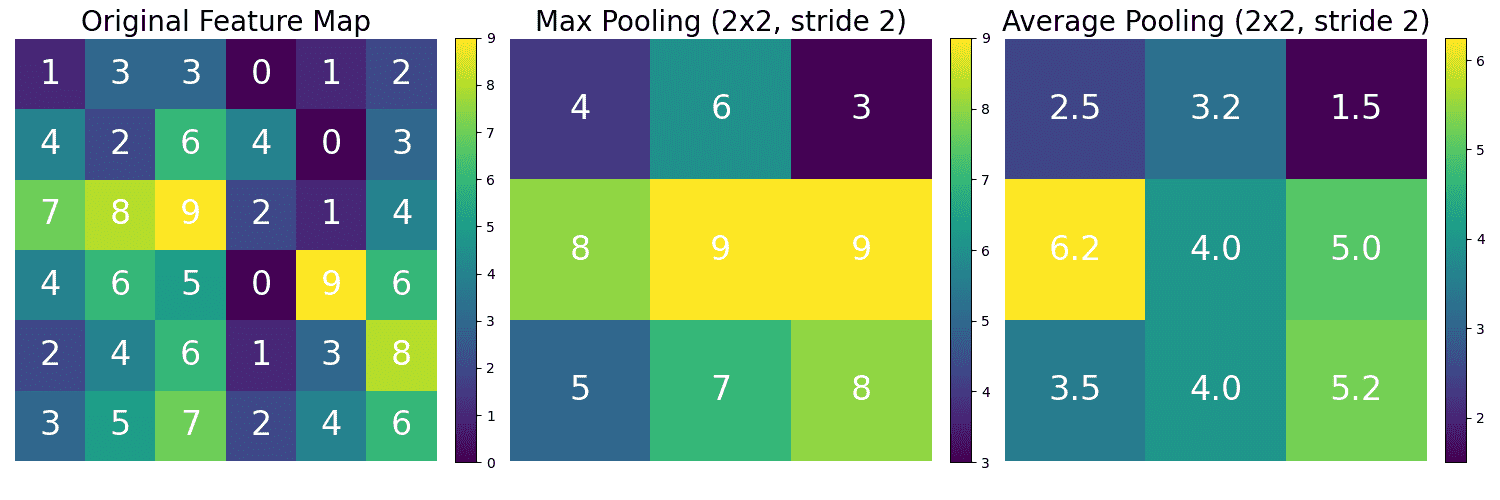
Below is a 2D image example for using zero padding in CNN.
(2) Retains Boundary Information: Ensures edge pixels are processed adequately.
(3) Enables Larger Kernels: Allows using bigger filters without excessive size reduction.
(4) Controls Output Size: Provides a mechanism to manage the dimensions of output feature maps.
Beyond CNNs, zero padding plays a vital role in deep learning by standardizing variable-length sequences in tasks like NLP and time-series modeling. It ensures inputs have uniform dimensions for efficient batching and computation, enhances frequency resolution in spectral analyses, and allows for effective loss masking to focus learning on actual data.
(1) Standardizing Variable-Length Inputs: In NLP and time-series analysis, zero padding ensures that sequences of varying lengths have a uniform size. This uniformity is crucial for batch processing and for models like recurrent neural networks (RNNs) or transformers.
(2) Attention Masking in Transformers: Padding tokens in Transformer inputs are assigned zero values and then excluded via padding masks in self-attention layers, preventing the model from attending to irrelevant positions in the sequence.
 (its activation) and a weighted sum
(its activation) and a weighted sum  computed as:
computed as:

 is the target value.
is the target value. 


 that feeds into the output neurons. Its contribution to the loss is influenced by all neurons it connects to in the subsequent layer. The backpropagated error for neuron
that feeds into the output neurons. Its contribution to the loss is influenced by all neurons it connects to in the subsequent layer. The backpropagated error for neuron 
 is the derivative of the activation function at neuron
is the derivative of the activation function at neuron  for a neuron, the gradient with respect to a weight
for a neuron, the gradient with respect to a weight  connected to input
connected to input  is:
is:



 represents the receptive field size in layer
represents the receptive field size in layer  .
.  for the input layer.
for the input layer. represents the kernel size of layer
represents the kernel size of layer  represents the stride of layer
represents the stride of layer 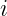 .
.