What is the role of CNNs in object detection and segmentation?
Answer
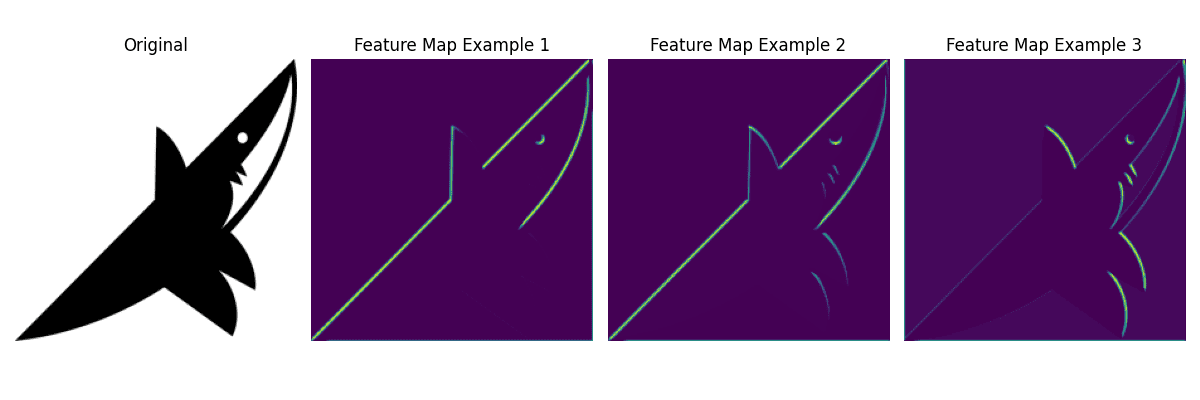
In object detection and segmentation, a CNN commonly acts as a spatial feature extractor that converts pixels into a hierarchy of increasingly semantic feature maps. Detection heads use those features to classify objects and localize bounding boxes, while segmentation heads upsample and fuse spatial detail to predict per-pixel classes or instance-specific masks. Multiscale features are important because small objects need high-resolution maps and large objects benefit from deeper receptive fields. CNNs are therefore the backbone and often part of the head, but proposal logic, feature pyramids, decoders, and task losses complete the system; modern vision Transformers can also replace or complement the CNN backbone.

Figure 1: A shared convolutional feature hierarchy supports two different outputs: sparse boxes and classes versus dense semantic or instance masks.
(1) Shared Backbone: Convolutions provide translation-equivariant local processing and reusable feature maps at several strides.
(2) Detection Role: One-stage or region-based heads turn features into class scores and box coordinates, often using multiscale pyramids.
(3) Segmentation Role: Dense decoders combine semantic context with fine spatial detail for semantic labels, instance masks, or panoptic outputs.

Figure 2: Task-specific paths after the backbone show what each head must predict and how its output aligns with the input image.
Mathematical Formulation:




Where:
 is the input image and
is the input image and  is the backbone feature map produced by stage
is the backbone feature map produced by stage  .
. is the multiscale feature set supplied to task heads.
is the multiscale feature set supplied to task heads. is the detection head, with
is the detection head, with  denoting predicted boxes and
denoting predicted boxes and  predicted class probabilities.
predicted class probabilities. is the segmentation head and
is the segmentation head and  is its dense output mask or logit tensor.
is its dense output mask or logit tensor. and
and  are output height and width, while is the number of semantic classes or mask channels.
are output height and width, while is the number of semantic classes or mask channels.
 is the input image and
is the input image and  is the backbone feature map produced by stage
is the backbone feature map produced by stage  .
. is the multiscale feature set supplied to task heads.
is the multiscale feature set supplied to task heads. is the detection head, with
is the detection head, with  denoting predicted boxes and
denoting predicted boxes and  predicted class probabilities.
predicted class probabilities. is the segmentation head and
is the segmentation head and  is its dense output mask or logit tensor.
is its dense output mask or logit tensor.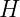 and
and  are output height and width, while
are output height and width, while  is the number of semantic classes or mask channels.
is the number of semantic classes or mask channels. mask. Modules such as SE use channel attention, while CBAM applies channel attention followed by spatial attention to refine both feature type and location.
mask. Modules such as SE use channel attention, while CBAM applies channel attention followed by spatial attention to refine both feature type and location.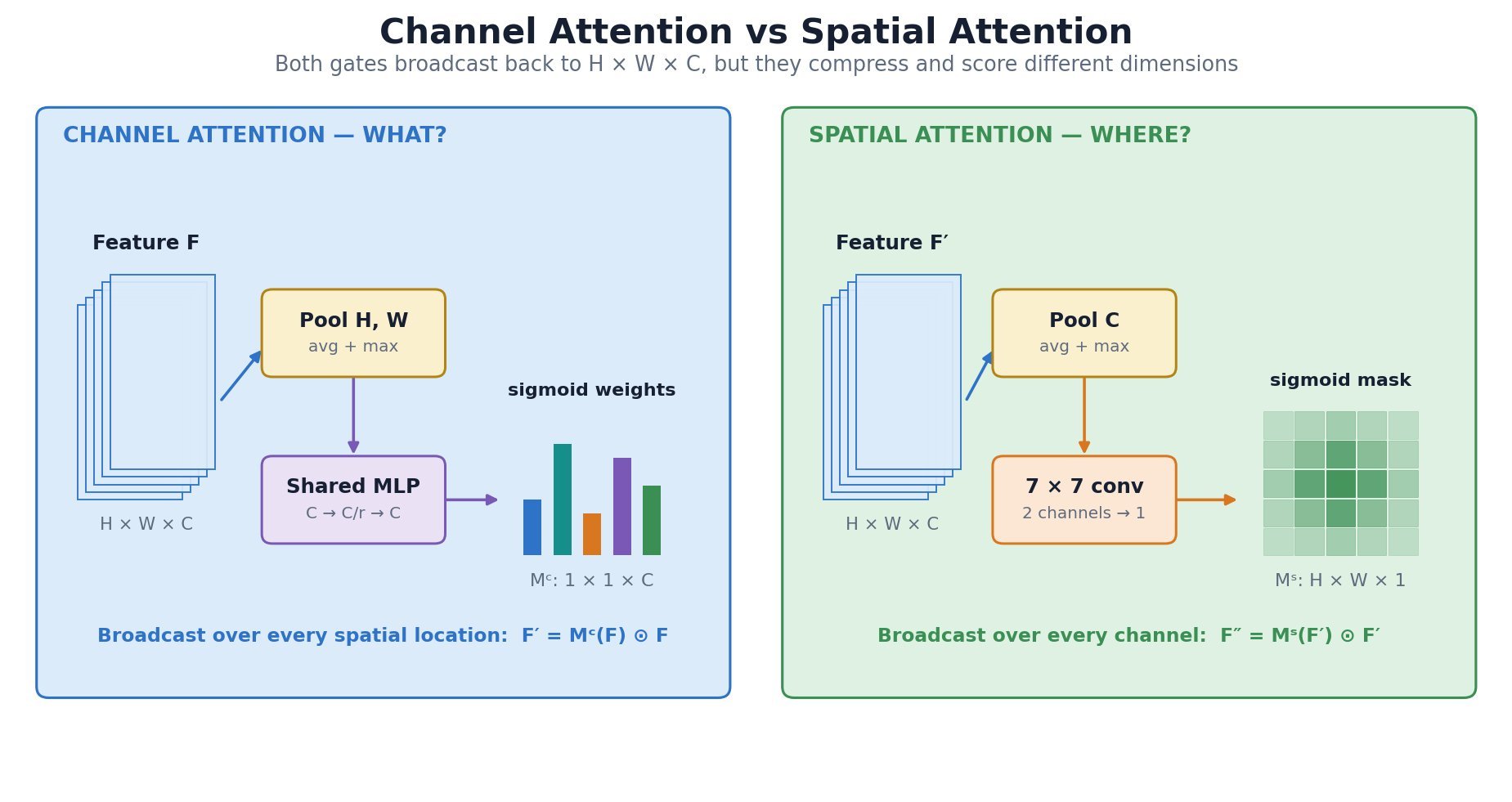
 multiplicative weights.
multiplicative weights.

![M_s(F)=\sigma\!\left(f^{7\times7}([\mathrm{AvgPool}_{c}(F);\mathrm{MaxPool}_{c}(F)])\right)](https://s0.wp.com/latex.php?latex=M_s%28F%29%3D%5Csigma%5C%21%5Cleft%28f%5E%7B7%5Ctimes7%7D%28%5B%5Cmathrm%7BAvgPool%7D_%7Bc%7D%28F%29%3B%5Cmathrm%7BMaxPool%7D_%7Bc%7D%28F%29%5D%29%5Cright%29&bg=ffffff&fg=000&s=3&c=20201002)
 is the input feature map with height
is the input feature map with height  is the channel mask; spatial average/max pooling and the shared
is the channel mask; spatial average/max pooling and the shared  produce channel logits.
produce channel logits. is the spatial mask; channel pooling outputs are concatenated by
is the spatial mask; channel pooling outputs are concatenated by ![[\,;\,]](https://s0.wp.com/latex.php?latex=%5B%5C%2C%3B%5C%2C%5D&bg=ffffff&fg=000&s=2&c=20201002) and filtered by
and filtered by  .
. is the sigmoid function;
is the sigmoid function;  broadcasts over
broadcasts over  , while
, while  broadcasts over
broadcasts over  filter per input channel, so it learns spatial patterns independently; the
filter per input channel, so it learns spatial patterns independently; the  pointwise stage combines those channel responses into new output channels. This factorization can reduce multiply-accumulates and parameters by almost the kernel area when channel counts are large. It is common in MobileNet, Xception, EfficientNet-style mobile blocks, and edge models where latency, power, and model size matter.
pointwise stage combines those channel responses into new output channels. This factorization can reduce multiply-accumulates and parameters by almost the kernel area when channel counts are large. It is common in MobileNet, Xception, EfficientNet-style mobile blocks, and edge models where latency, power, and model size matter.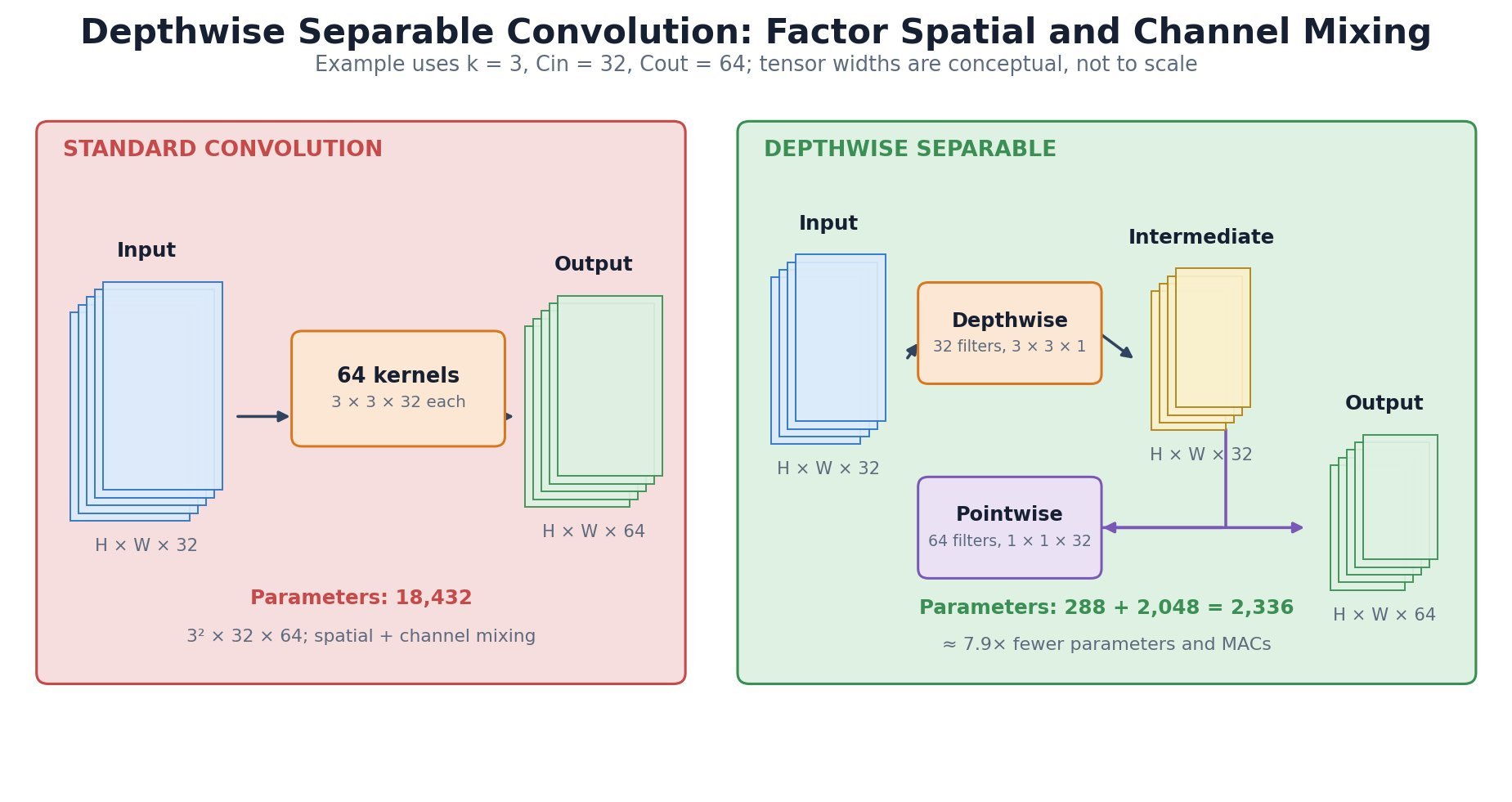
 independent
independent  channel transformation independently at every spatial position.
channel transformation independently at every spatial position.



 and
and  count multiply-accumulates for standard and depthwise-separable convolution.
count multiply-accumulates for standard and depthwise-separable convolution. is the square spatial-kernel width.
is the square spatial-kernel width. are input and output channel counts; the formula assumes depth multiplier
are input and output channel counts; the formula assumes depth multiplier  .
. and large
and large  .
.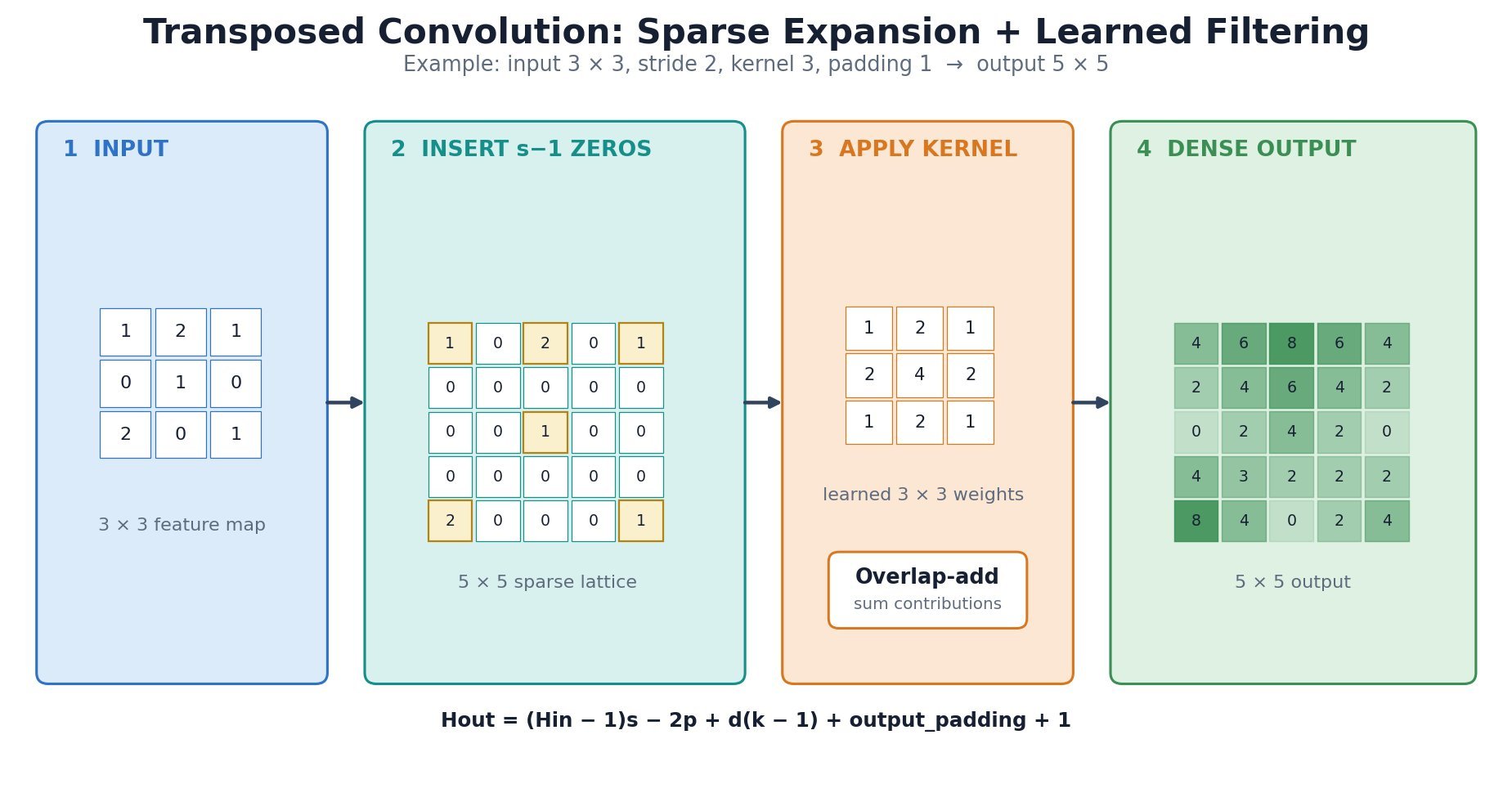
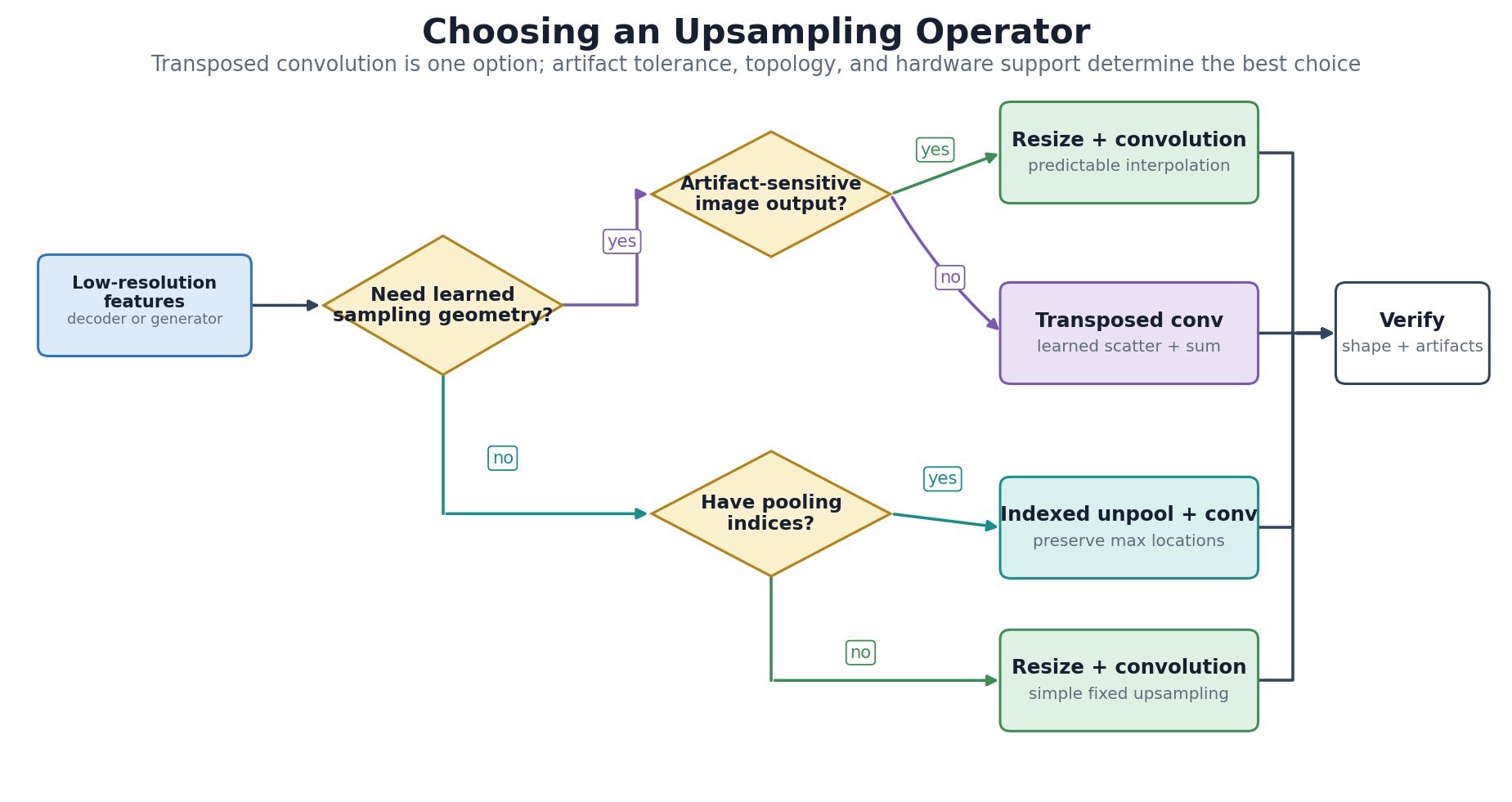

 and
and  are the input and output sizes along one spatial axis.
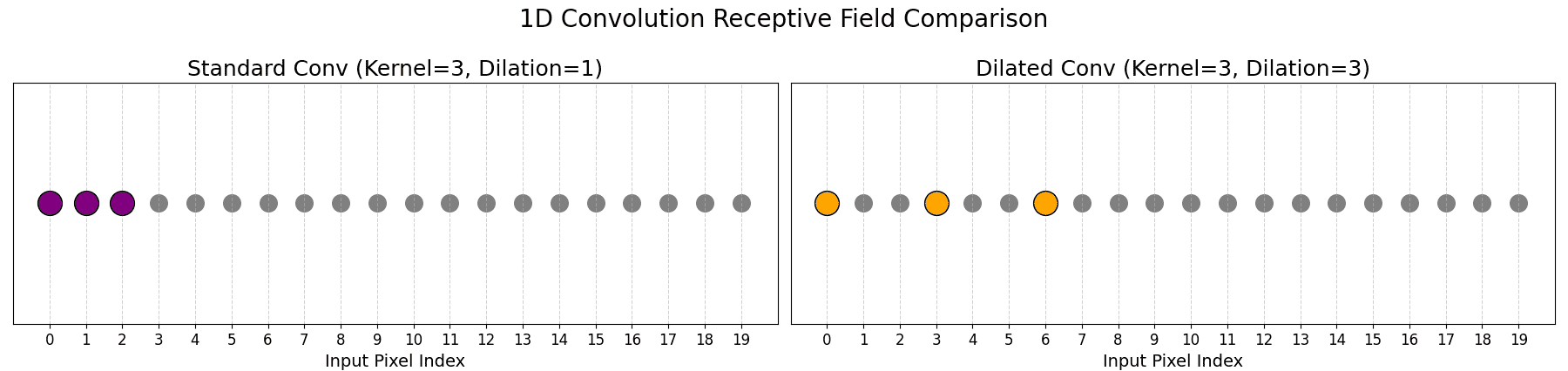
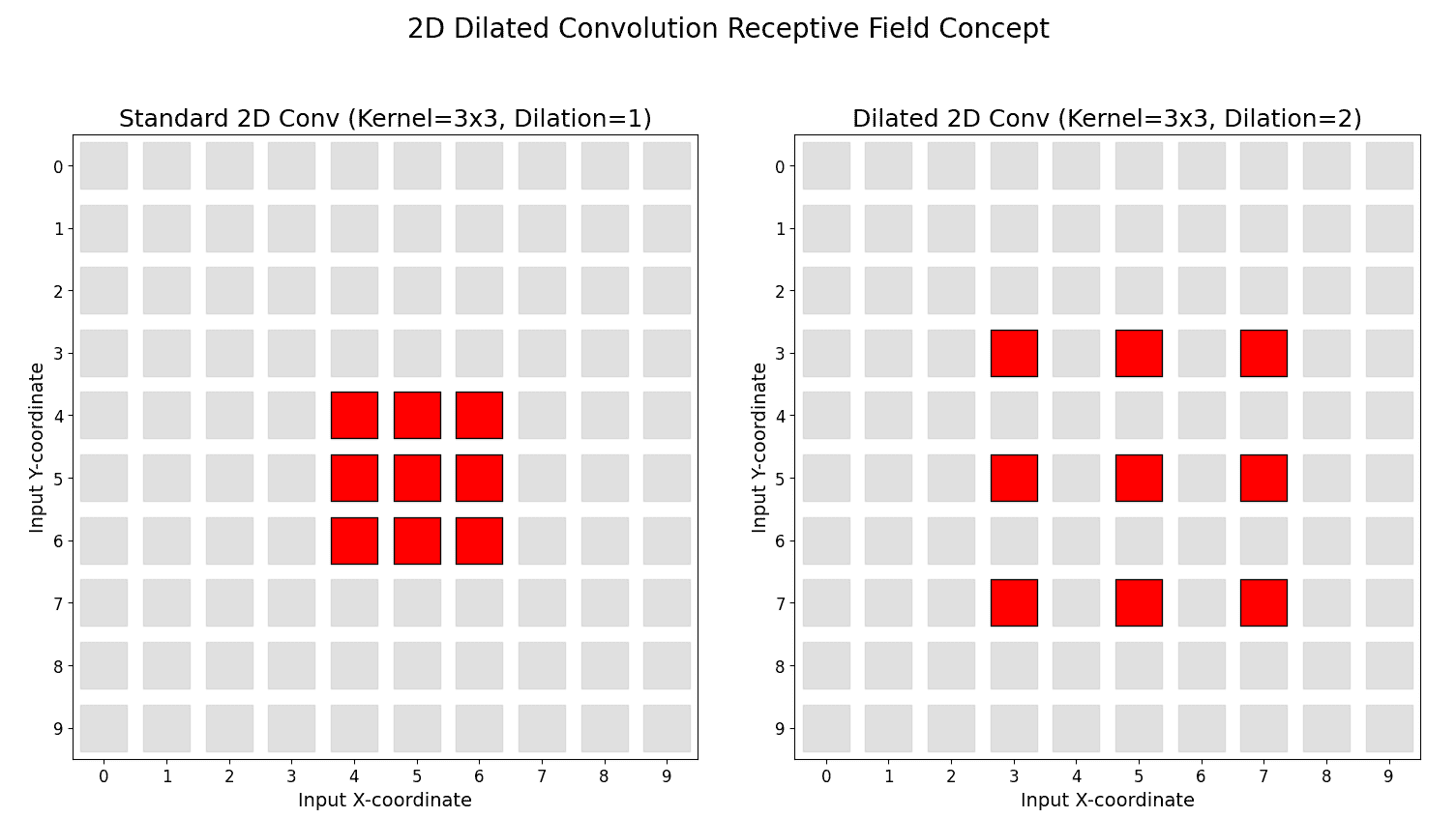
are the input and output sizes along one spatial axis. is stride,
is stride, 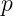 is padding,
is padding,  is dilation, and
is dilation, and  is output padding used to choose among otherwise ambiguous valid output sizes; it does not append learned pixels.
is output padding used to choose among otherwise ambiguous valid output sizes; it does not append learned pixels. maps combine localization detail with high-level context. Detection, instance segmentation, and keypoint heads can then select a pyramid level appropriate to each object or region scale.
maps combine localization detail with high-level context. Detection, instance segmentation, and keypoint heads can then select a pyramid level appropriate to each object or region scale.
 reduce spatial resolution while increasing receptive field and semantic abstraction.
reduce spatial resolution while increasing receptive field and semantic abstraction. or
or  , while large objects use coarser levels such as
, while large objects use coarser levels such as  or
or  .
.


 is the bottom-up backbone feature and
is the bottom-up backbone feature and  is the fused pyramid output at level
is the fused pyramid output at level  aligns channel width,
aligns channel width,  doubles spatial resolution, and
doubles spatial resolution, and  smooths the merged feature.
smooths the merged feature. is the reference level, and
is the reference level, and  are the region width and height.
are the region width and height. is the canonical reference scale and
is the canonical reference scale and  maps the continuous log-scale value to a discrete level.
maps the continuous log-scale value to a discrete level.
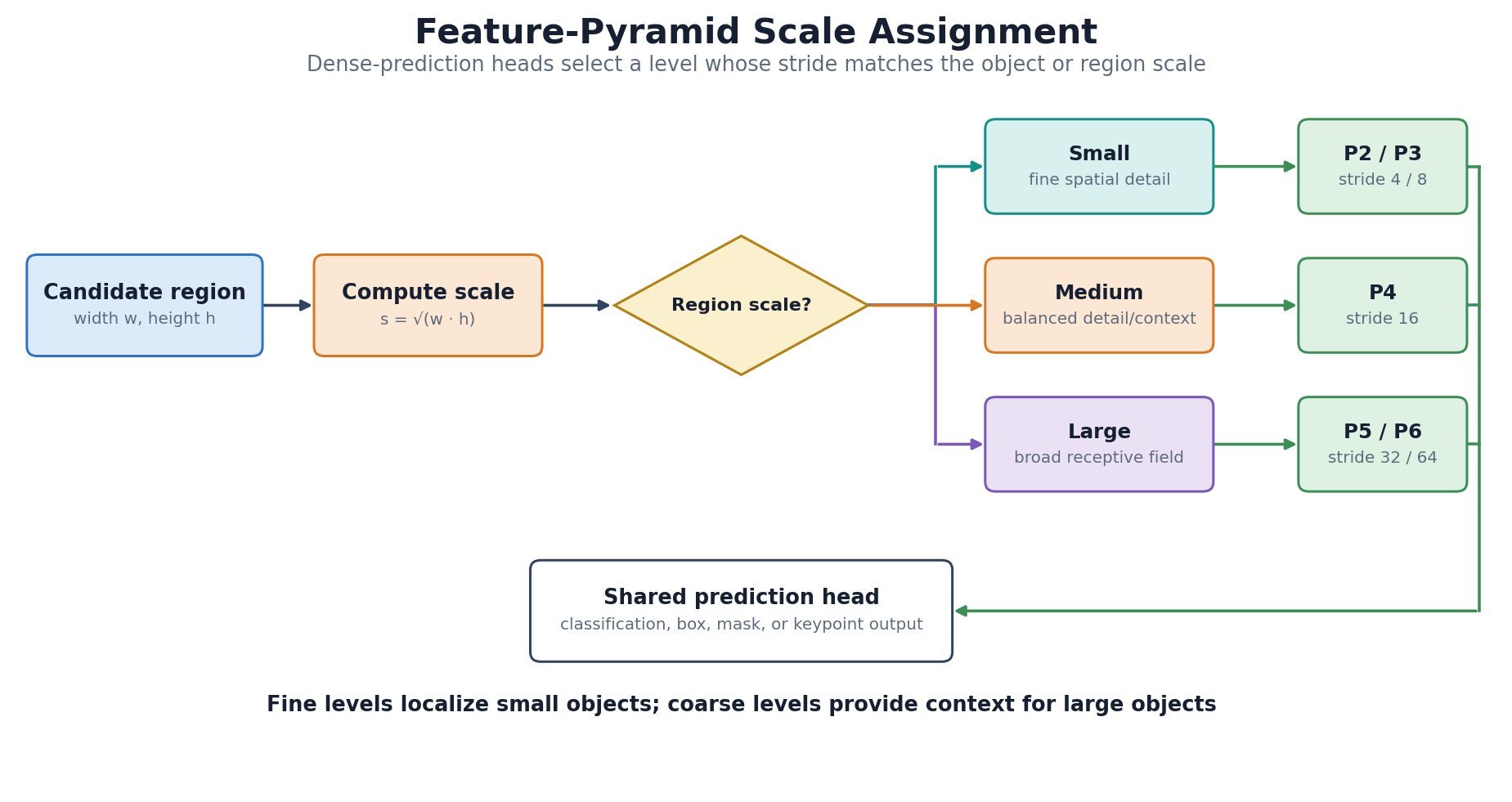
 ; a 3D kernel adds
; a 3D kernel adds  and jointly traverses depth or time.
and jointly traverses depth or time.
 and
and  are the input and output tensors, while
are the input and output tensors, while  indexes output channels and
indexes output channels and  indexes input channels.
indexes input channels. index output depth/time, height, and width;
index output depth/time, height, and width;  range over the kernel support along those axes.
range over the kernel support along those axes. are removed, leaving only spatial indices
are removed, leaving only spatial indices  ; stride, padding, and dilation modify each active index mapping.
; stride, padding, and dilation modify each active index mapping.