Explain the concept of “Sparsity” in neural networks.
Answer
Sparsity in neural networks refers to the property that many parameters (weights) or activations are exactly zero (or very close to zero).
This leads to lighter, faster, and more interpretable models. Techniques such as L1 regularization, pruning, and ReLU activations help enforce sparsity, making networks more efficient without compromising performance.
Common techniques and their equations:
(1) L1 Regularization (encourages sparse weights)
Where: represents the i-th model weight
represents the i-th model weight controls the strength of sparsity
controls the strength of sparsity
(2) ReLU Activation (induces sparse activations)
Where: is the neuron input.
is the neuron input.
The plot below shows weight distributions trained without using L1 and with L1-induced sparsity.
Login to view more content

 is the effective weight matrix.
is the effective weight matrix. is the effective bias.
is the effective bias.
 is the input dimension.
is the input dimension. is the output dimension of that layer.
is the output dimension of that layer.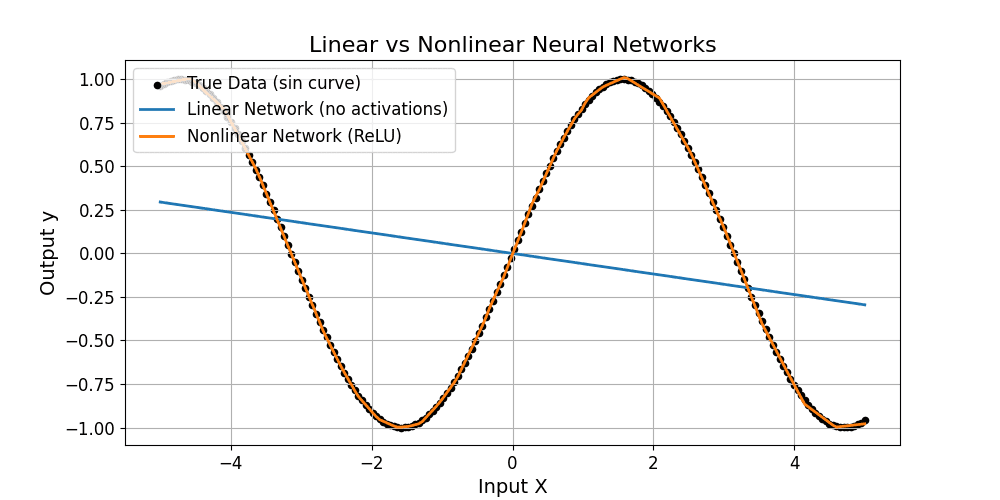



 is the predicted output (0 or 1)
is the predicted output (0 or 1) is the weight vector
is the weight vector is the bias term
is the bias term is the activation function (typically a step function)
is the activation function (typically a step function)

