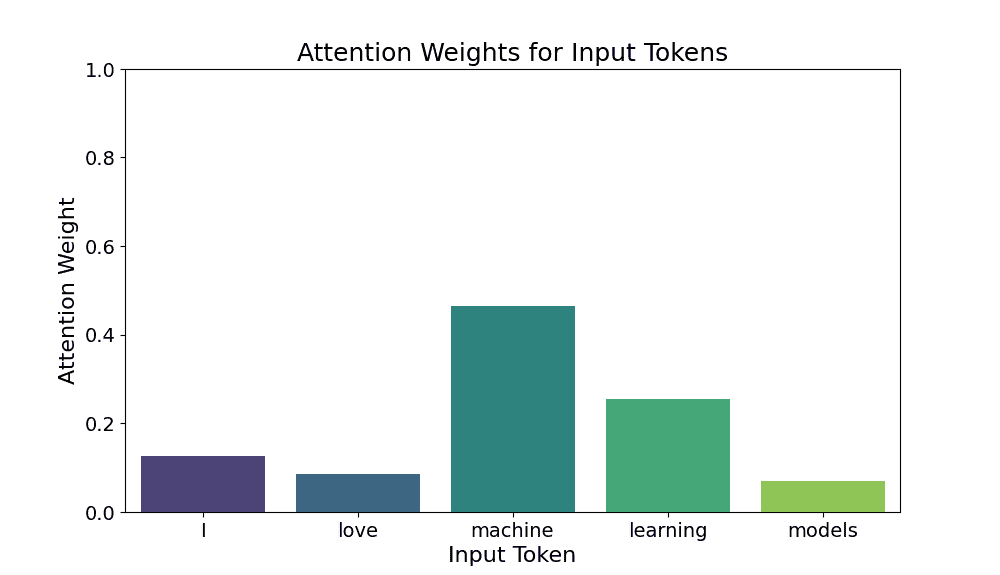
What is layer normalization, and why is it used in Transformers?
Answer
Layer Normalization is a technique that standardizes the inputs across the features for a single training example. Unlike Batch Normalization, which normalizes across the batch dimension, Layer Normalization computes the mean and variance for every single example independently to normalize its features.
(1) Normalization within a Sample: Layer Normalization (LN) calculates the mean and variance across all the features of a single data point (e.g., a single token’s embedding vector in a sequence). It then uses these statistics to normalize the features for that data point only.
(2) Batch Size Independence: Because it operates on individual examples, its calculations are independent of the batch size. This is a major advantage in models like Transformers that often process sequences of varying lengths, which can make batch statistics unstable.
(3) Stabilizes Training: By keeping the activations in each layer within a consistent range (mean of 0, standard deviation of 1), LN helps prevent the exploding or vanishing gradients problem. This leads to a smoother training process and faster convergence, especially in deep networks.
Layer Normalization Equation:
Where: = input feature,
= input feature, = mean of all features for the current sample,
= mean of all features for the current sample, = standard deviation of all features,
= standard deviation of all features, = small constant for numerical stability,
= small constant for numerical stability, = learnable scale and shift parameters.
= learnable scale and shift parameters.
The figure below demonstrates the difference between batch normalization and layer normalization.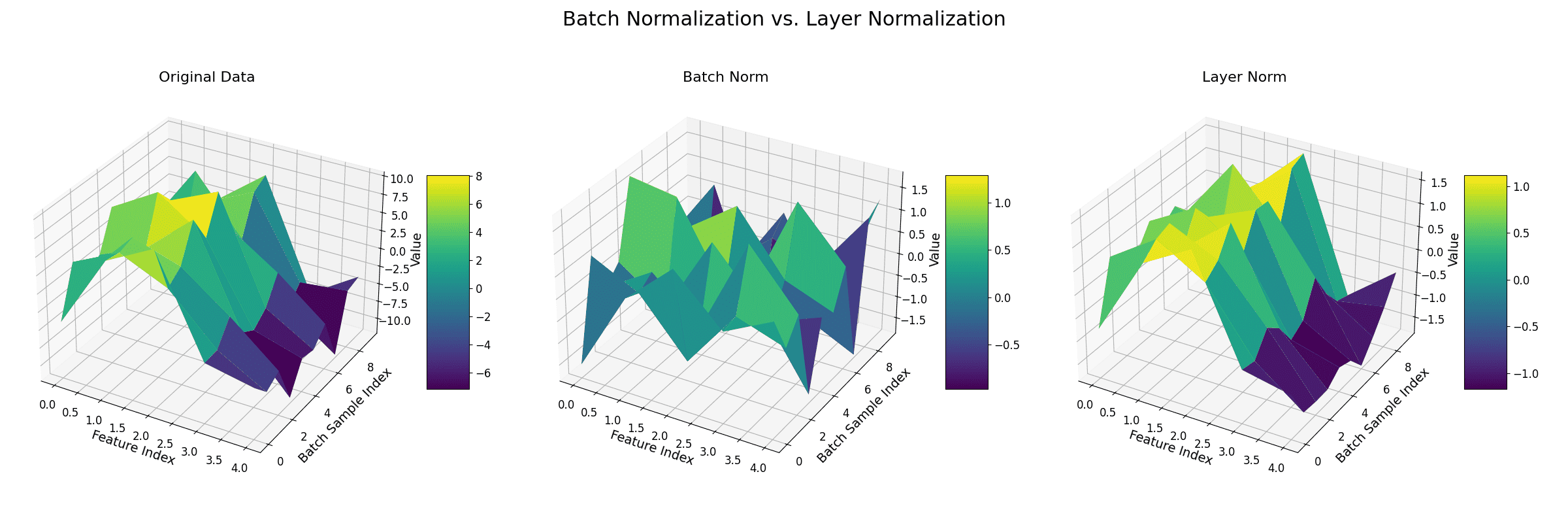
 ): Cost is relatively small; attention score matrix overhead is minimal. Q, K, and V projections together dominate the compute.
): Cost is relatively small; attention score matrix overhead is minimal. Q, K, and V projections together dominate the compute. 

 is large.
is large.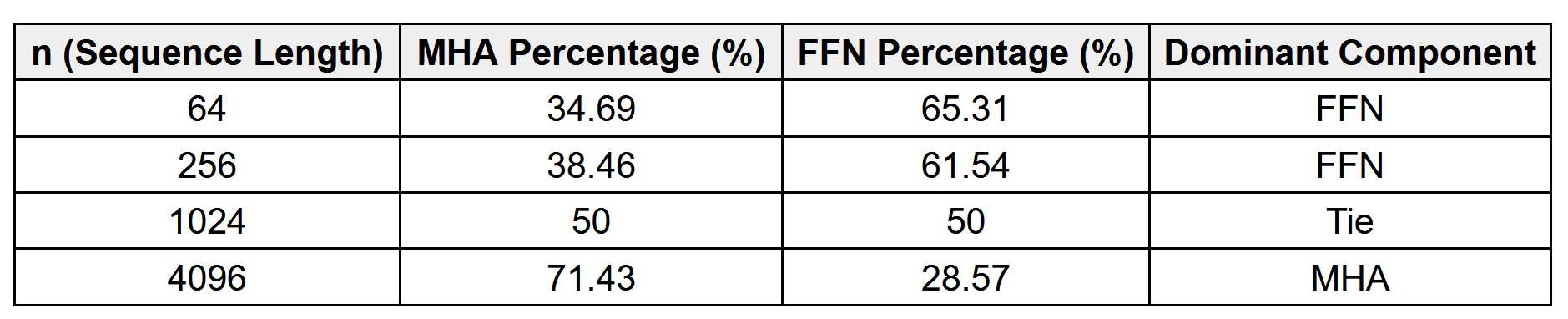
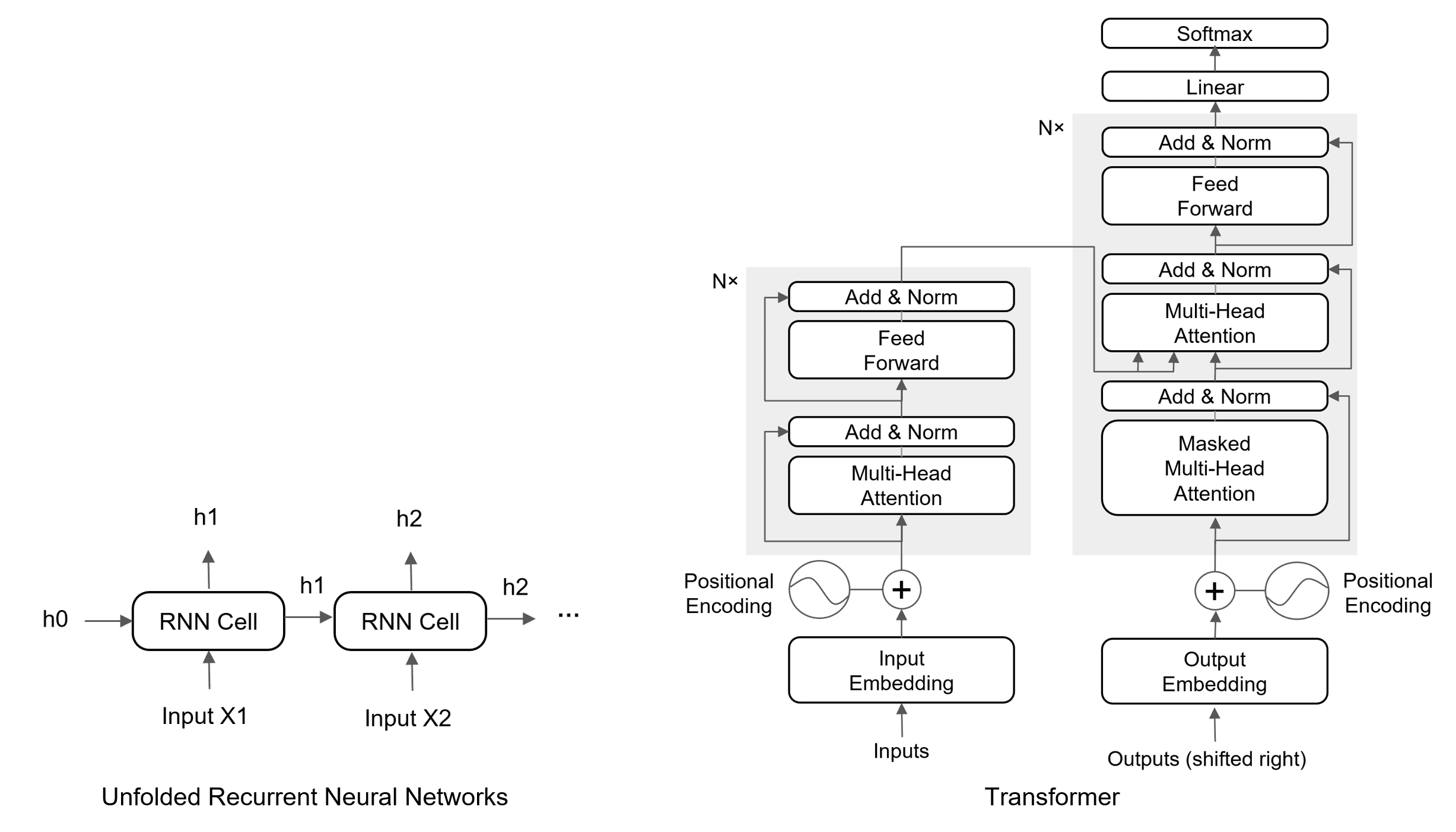

 — input vector for a token after the attention layer
— input vector for a token after the attention layer — trainable weight matrices
— trainable weight matrices — trainable bias vectors
— trainable bias vectors — ReLU activation (sometimes replaced by GELU)
— ReLU activation (sometimes replaced by GELU)

 : token position in the sequence
: token position in the sequence : dimension index
: dimension index : embedding dimension
: embedding dimension
 to a lower bound depending on the sparsity pattern.
to a lower bound depending on the sparsity pattern. is computed only at dilated positions:
is computed only at dilated positions:
 are the dilated subsets of keys and values.
are the dilated subsets of keys and values. is the key dimension.
is the key dimension.
 (e.g., the token itself and
(e.g., the token itself and  neighbors).
neighbors). .
.



 : Final output projection matrix that maps the concatenated attention outputs back to the original model dimension.
: Final output projection matrix that maps the concatenated attention outputs back to the original model dimension. : Number of attention heads.
: Number of attention heads. : Dimension of each head’s projected subspace.
: Dimension of each head’s projected subspace.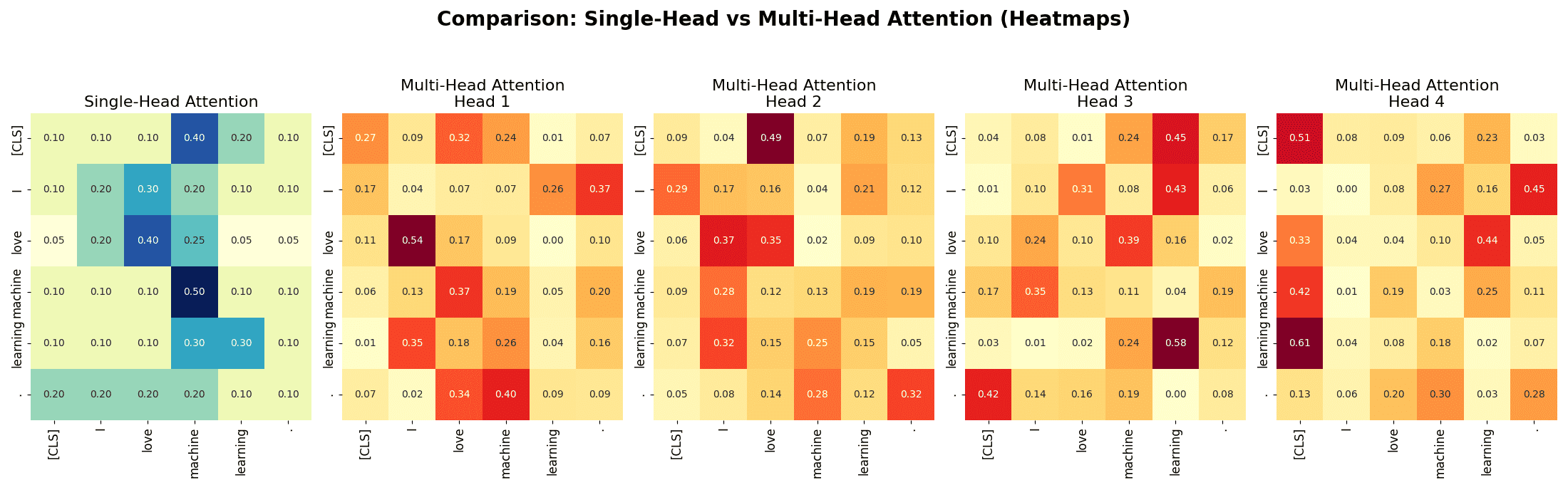

 ,
,  , and
, and  represent query, key, and value matrices, respectively
represent query, key, and value matrices, respectively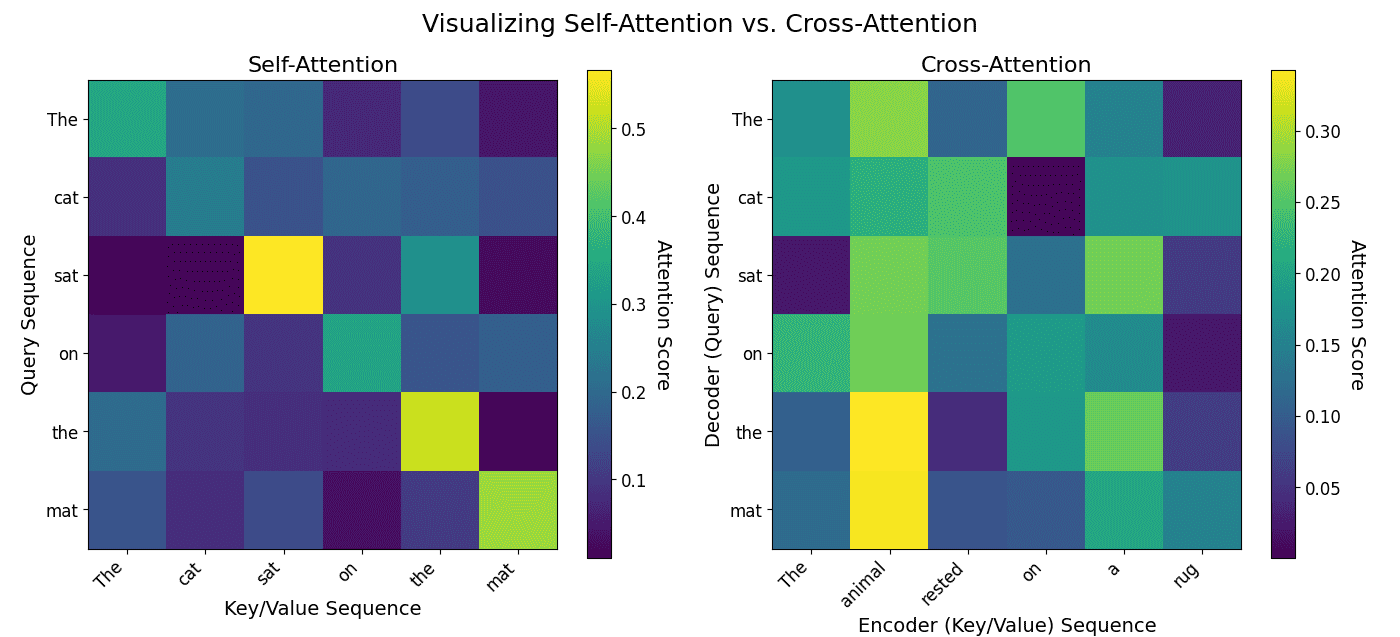

 : Matrices of queries, keys, and values.
: Matrices of queries, keys, and values. : Converts similarity scores to probabilities.
: Converts similarity scores to probabilities.