What is Multi-Query Attention in transformer models?
Answer
Multi-Query Attention (MQA) optimizes the standard Multi-Head Attention (MHA) in transformers by using multiple query heads while sharing a single key-value projection across them. This design maintains similar computational expressiveness to MHA but significantly reduces memory usage during inference, especially in KV caching for autoregressive tasks, making it ideal for scaling large models. It trades minor potential quality for efficiency.
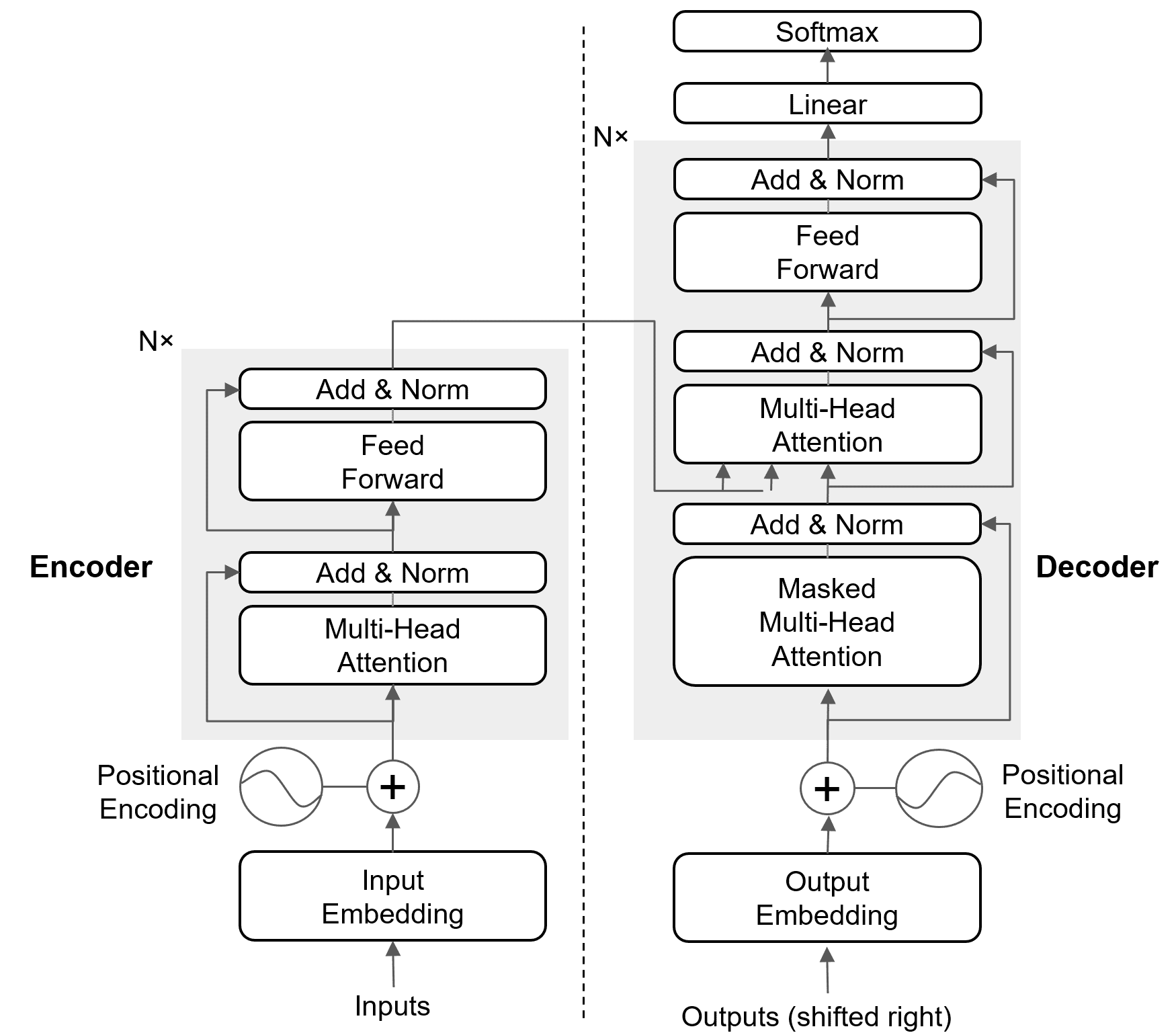
Comparison to Multi-Head Attention (MHA): In standard MHA, each attention head has independent projections for queries (Q), keys (K), and values (V). In MQA, only Q is projected into multiple heads, while K and V use a single projection shared across all query heads, as shown in the figure below.
Efficiency Benefits: Reduces memory footprint during inference, particularly with KV caching, as the cache stores only one set of K and V vectors instead of one per head, lowering memory complexity from O(n * h * d) to O(n * d), where n is sequence length, h is number of heads, and d is head dimension.
The core attention operation for a single head in MQA can be represented by the following equation:
Where: represents the query vector for the ith attention head.
represents the query vector for the ith attention head. and
and  represent the single, shared key and value vectors used by all heads.
represent the single, shared key and value vectors used by all heads. is the dimension of the key vectors.
is the dimension of the key vectors.

 = query of the current token t.
= query of the current token t. = cached keys and values for all tokens up to t.
= cached keys and values for all tokens up to t.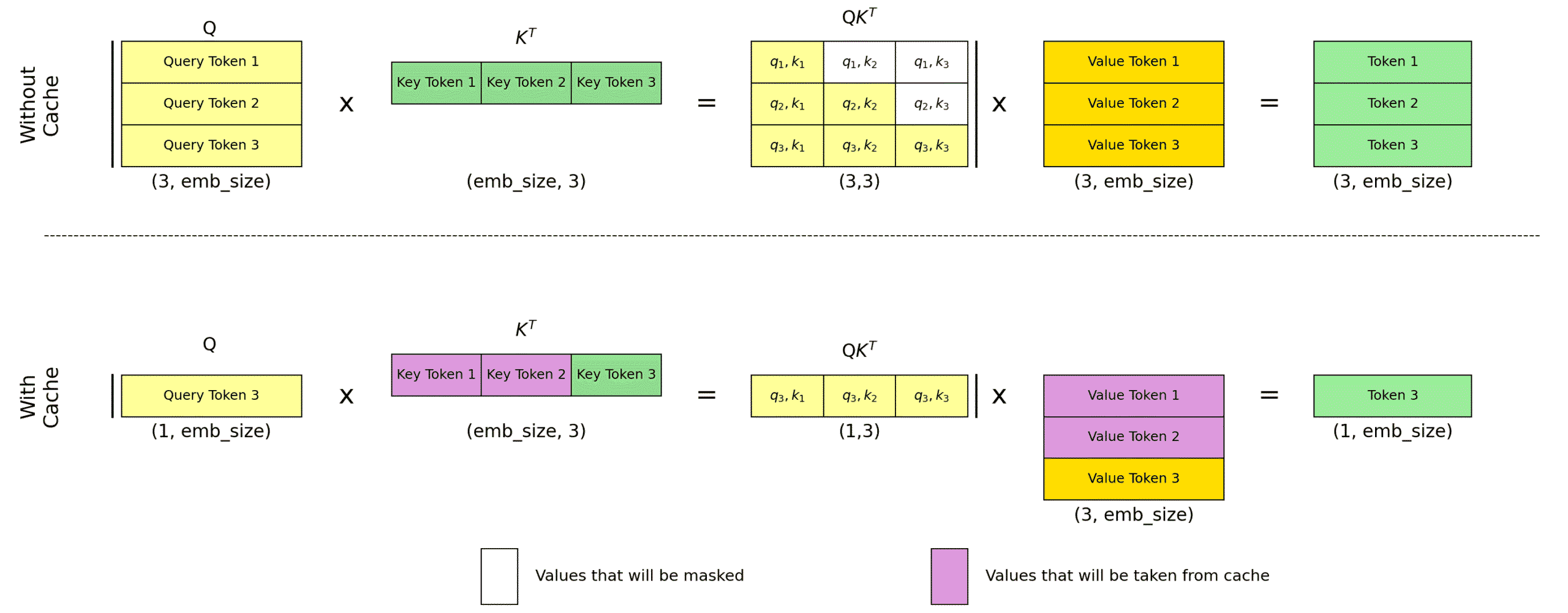

 , hidden dimension =
, hidden dimension =  , number of heads =
, number of heads =  .
. is projected into queries, keys, and values.
is projected into queries, keys, and values. (for all 3 matrices).
(for all 3 matrices).




 = raw score for position
= raw score for position 

 applied to values
applied to values  :
:


 , the dominant term is:
, the dominant term is: .
.

 query matrix.
query matrix. key matrix.
key matrix. value matrix.
value matrix. mask matrix with 0 for allowed positions and large negative values (e.g., −∞) for disallowed positions.
mask matrix with 0 for allowed positions and large negative values (e.g., −∞) for disallowed positions.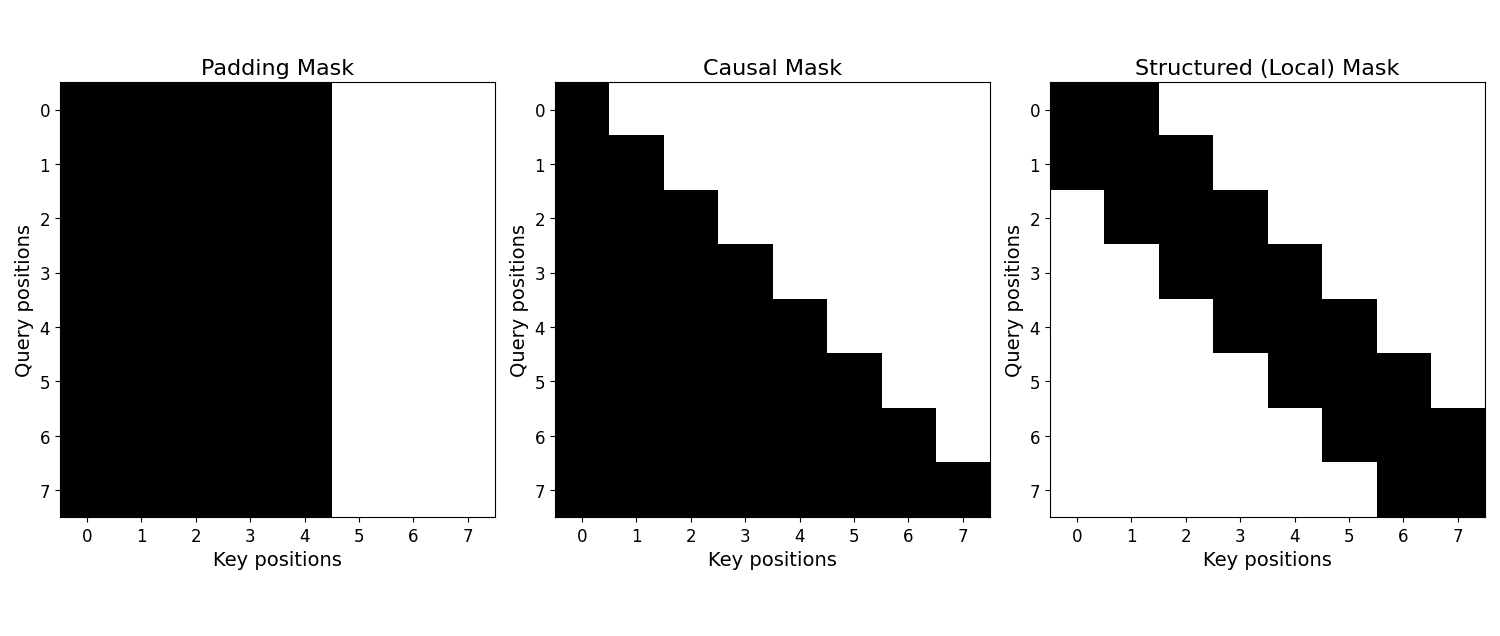

 is the logit for token
is the logit for token 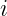 , computed using the embedding matrix
, computed using the embedding matrix  .
. is the hidden representation from the Transformer.
is the hidden representation from the Transformer. is the vocabulary size.
is the vocabulary size.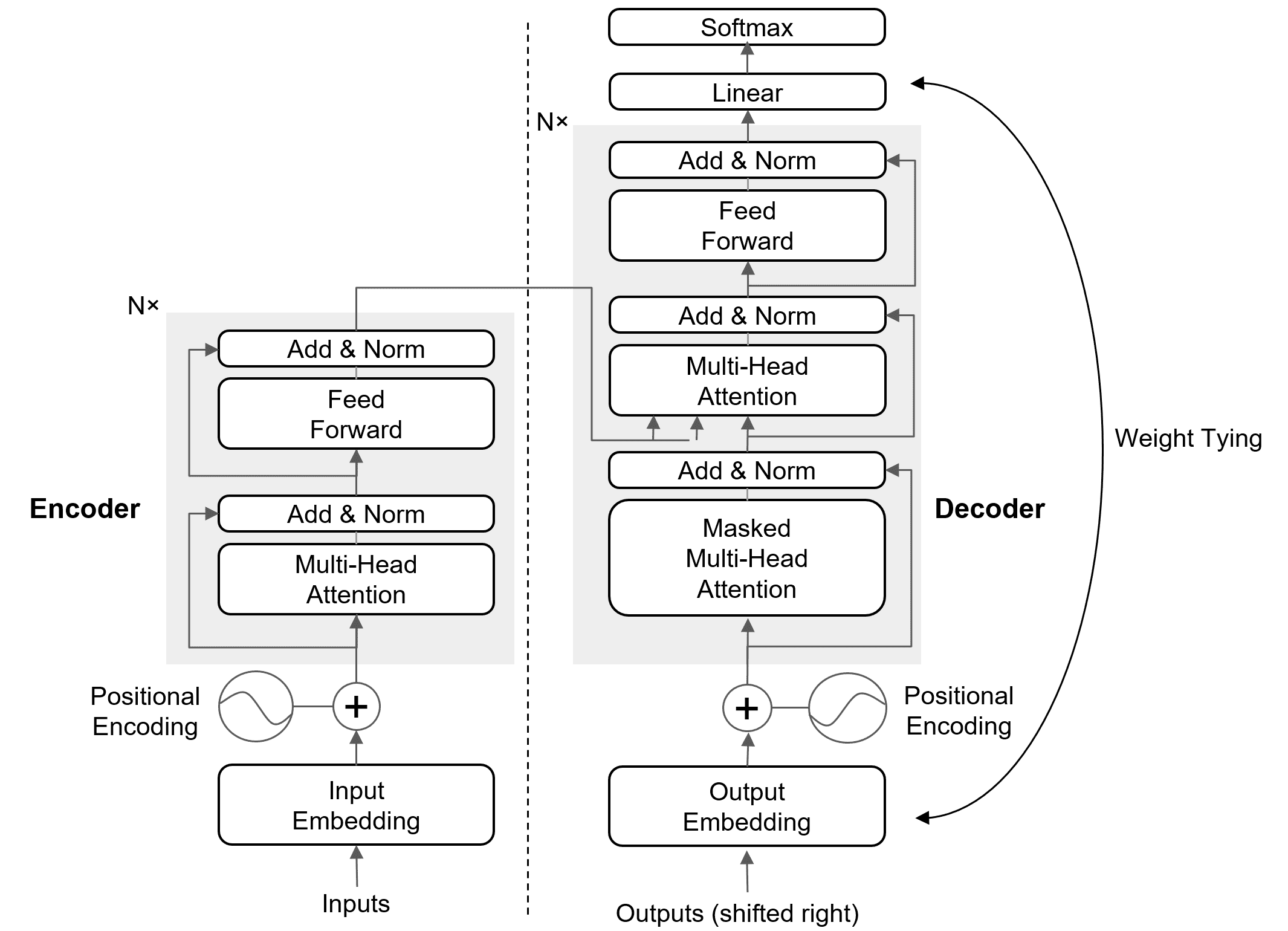
![\mbox{GELU}(x) = x \cdot \Phi(x) = x \cdot \frac{1}{2}\left[1 + \mbox{erf}\left(\frac{x}{\sqrt{2}}\right)\right]](https://s0.wp.com/latex.php?latex=%5Cmbox%7BGELU%7D%28x%29+%3D+x+%5Ccdot+%5CPhi%28x%29+%3D+x+%5Ccdot+%5Cfrac%7B1%7D%7B2%7D%5Cleft%5B1+%2B+%5Cmbox%7Berf%7D%5Cleft%28%5Cfrac%7Bx%7D%7B%5Csqrt%7B2%7D%7D%5Cright%29%5Cright%5D&bg=ffffff&fg=000&s=3&c=20201002)
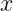 is the input,
is the input,  is the Cumulative Distribution Function (CDF) of the standard Gaussian.
is the Cumulative Distribution Function (CDF) of the standard Gaussian.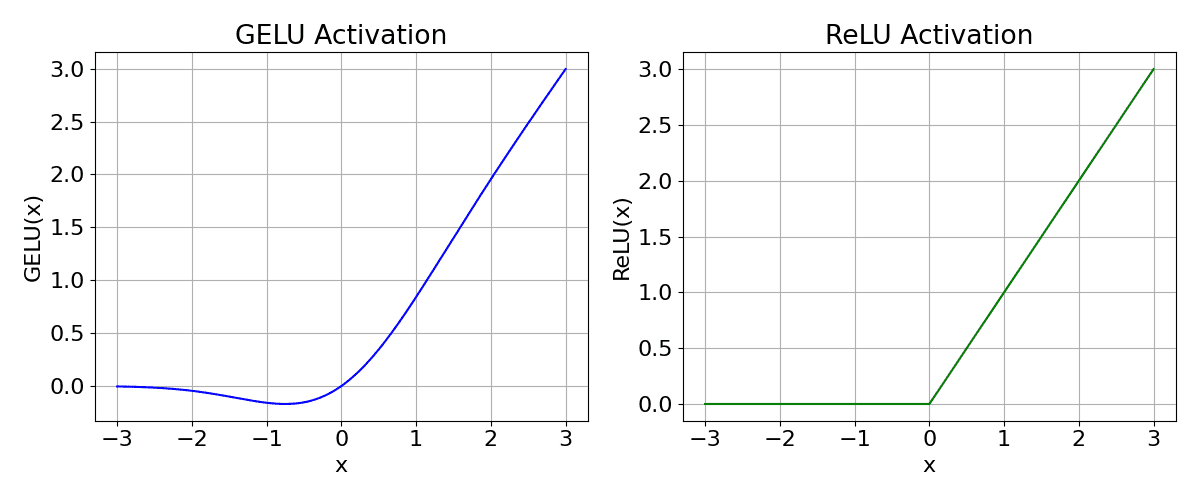
 represents the raw attention score for the i-th token,
represents the raw attention score for the i-th token,  and key
and key  grows larger when they point in similar directions, making it a natural similarity measure.
grows larger when they point in similar directions, making it a natural similarity measure.
 is the dot product similarity between query and key.
is the dot product similarity between query and key.
 , which is hardware-friendly.
, which is hardware-friendly.