How does BERT’s pre-training objective differ from GPT’s?
Answer
BERT is trained primarily with masked language modeling: selected input tokens are corrupted, and a bidirectional encoder predicts the original tokens from visible context on both sides. GPT uses causal language modeling: a decoder predicts each next token using only earlier tokens, enforced by a triangular attention mask. MLM supplies loss only at selected positions and creates a corruption mismatch between pre-training and ordinary inputs, whereas causal modeling supplies a target at nearly every position and matches left-to-right generation. Original BERT also used next sentence prediction, while standard GPT pre-training relies on the autoregressive token objective rather than NSP.

Figure 1: BERT reconstructs selected corrupted tokens from two-sided context, while GPT predicts the next token at every step from a left-only prefix.
(1) Context Visibility: BERT’s visible tokens attend bidirectionally; GPT position  cannot attend to positions later than .
cannot attend to positions later than .
(2) Prediction Targets: BERT reconstructs a selected masked subset, while GPT shifts the sequence and predicts the next token at each usable position.
(3) Downstream Bias: BERT naturally supports full-context understanding, whereas GPT’s objective directly trains open-ended autoregressive generation; either family can be adapted beyond that bias.
Mathematical Formulation:


Where:
 and
and  are the masked and causal language-modeling losses.
are the masked and causal language-modeling losses. is BERT’s selected target set and
is BERT’s selected target set and  indexes one target token
indexes one target token  .
. denotes BERT’s visible corrupted context outside the selected targets, and
denotes BERT’s visible corrupted context outside the selected targets, and  is the reconstruction probability.
is the reconstruction probability. indexes a GPT target position,
indexes a GPT target position,  is sequence length, and
is sequence length, and  is the preceding token prefix.
is the preceding token prefix. is the next-token probability and
is the next-token probability and  converts each probability into a log-likelihood term.
converts each probability into a log-likelihood term.
 and
and  are the masked and causal language-modeling losses.
are the masked and causal language-modeling losses. is BERT’s selected target set and
is BERT’s selected target set and  indexes one target token
indexes one target token  .
. denotes BERT’s visible corrupted context outside the selected targets, and
denotes BERT’s visible corrupted context outside the selected targets, and  is the reconstruction probability.
is the reconstruction probability. indexes a GPT target position,
indexes a GPT target position,  is sequence length, and
is sequence length, and  is the preceding token prefix.
is the preceding token prefix. is the next-token probability and
is the next-token probability and  converts each probability into a log-likelihood term.
converts each probability into a log-likelihood term.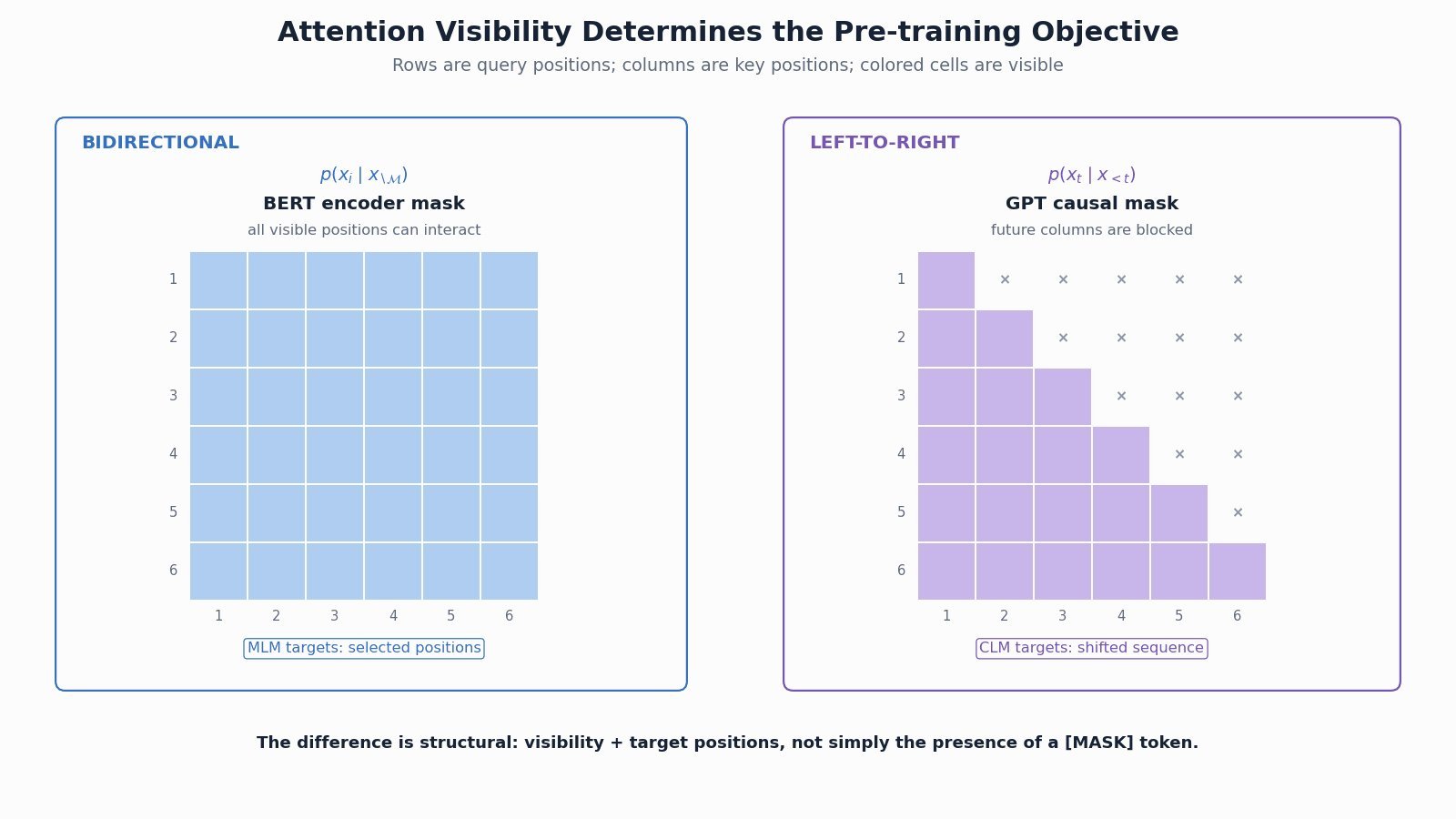
Figure 2: Attention visibility explains the objective difference: BERT uses a full visible-context matrix, while GPT uses a lower-triangular causal matrix.



 ,
,  , and
, and  are token, segment, and positional embedding matrices for the input sequence.
are token, segment, and positional embedding matrices for the input sequence. is the bidirectional Transformer stack and
is the bidirectional Transformer stack and 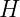 contains one contextual vector per input position.
contains one contextual vector per input position. is masked-language-modeling loss and
is masked-language-modeling loss and 


 ,
,  , and
, and  are query, key, and value matrices, and
are query, key, and value matrices, and  is the key width used for score scaling.
is the key width used for score scaling. assigns
assigns  to padded key positions so their softmax probabilities become zero.
to padded key positions so their softmax probabilities become zero. assigns
assigns  is later than query index
is later than query index 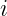 ; encoder-only models normally omit this mask.
; encoder-only models normally omit this mask. denotes one combined mask entry and is either
denotes one combined mask entry and is either  for an allowed connection or
for an allowed connection or  is batch size and
is batch size and  is padded sequence length, giving a dense token tensor of shape
is padded sequence length, giving a dense token tensor of shape  .
.
 mask. Modules such as SE use channel attention, while CBAM applies channel attention followed by spatial attention to refine both feature type and location.
mask. Modules such as SE use channel attention, while CBAM applies channel attention followed by spatial attention to refine both feature type and location.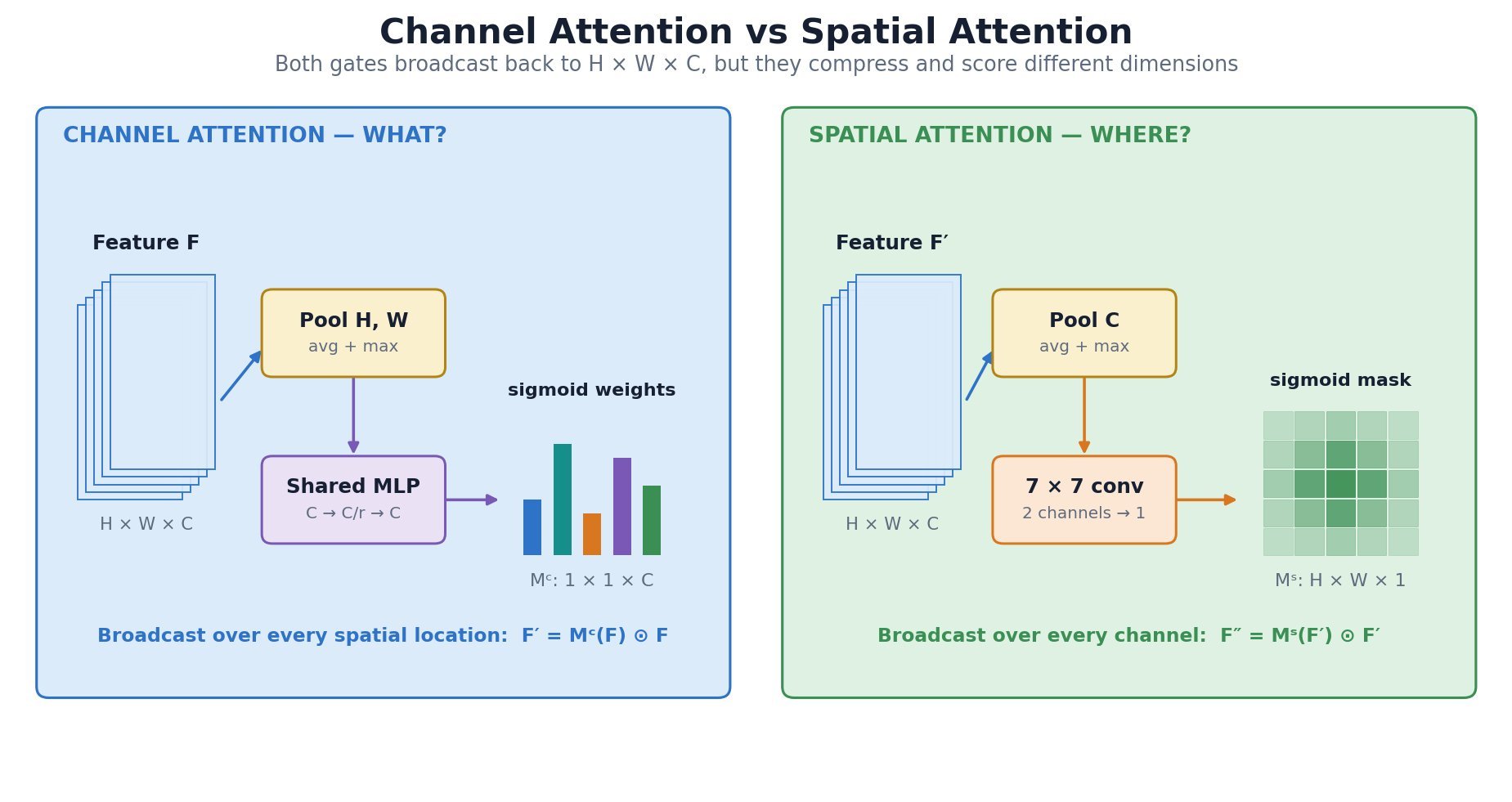
 multiplicative weights.
multiplicative weights.

![M_s(F)=\sigma\!\left(f^{7\times7}([\mathrm{AvgPool}_{c}(F);\mathrm{MaxPool}_{c}(F)])\right)](https://s0.wp.com/latex.php?latex=M_s%28F%29%3D%5Csigma%5C%21%5Cleft%28f%5E%7B7%5Ctimes7%7D%28%5B%5Cmathrm%7BAvgPool%7D_%7Bc%7D%28F%29%3B%5Cmathrm%7BMaxPool%7D_%7Bc%7D%28F%29%5D%29%5Cright%29&bg=ffffff&fg=000&s=3&c=20201002)
 is the input feature map with height
is the input feature map with height  , and
, and  is the channel mask; spatial average/max pooling and the shared
is the channel mask; spatial average/max pooling and the shared  produce channel logits.
produce channel logits. is the spatial mask; channel pooling outputs are concatenated by
is the spatial mask; channel pooling outputs are concatenated by ![[\,;\,]](https://s0.wp.com/latex.php?latex=%5B%5C%2C%3B%5C%2C%5D&bg=ffffff&fg=000&s=2&c=20201002) and filtered by
and filtered by  .
. is the sigmoid function;
is the sigmoid function;  broadcasts over
broadcasts over  , while
, while  broadcasts over
broadcasts over  score and probability matrices in high-bandwidth memory (HBM), it loads blocks of
score and probability matrices in high-bandwidth memory (HBM), it loads blocks of 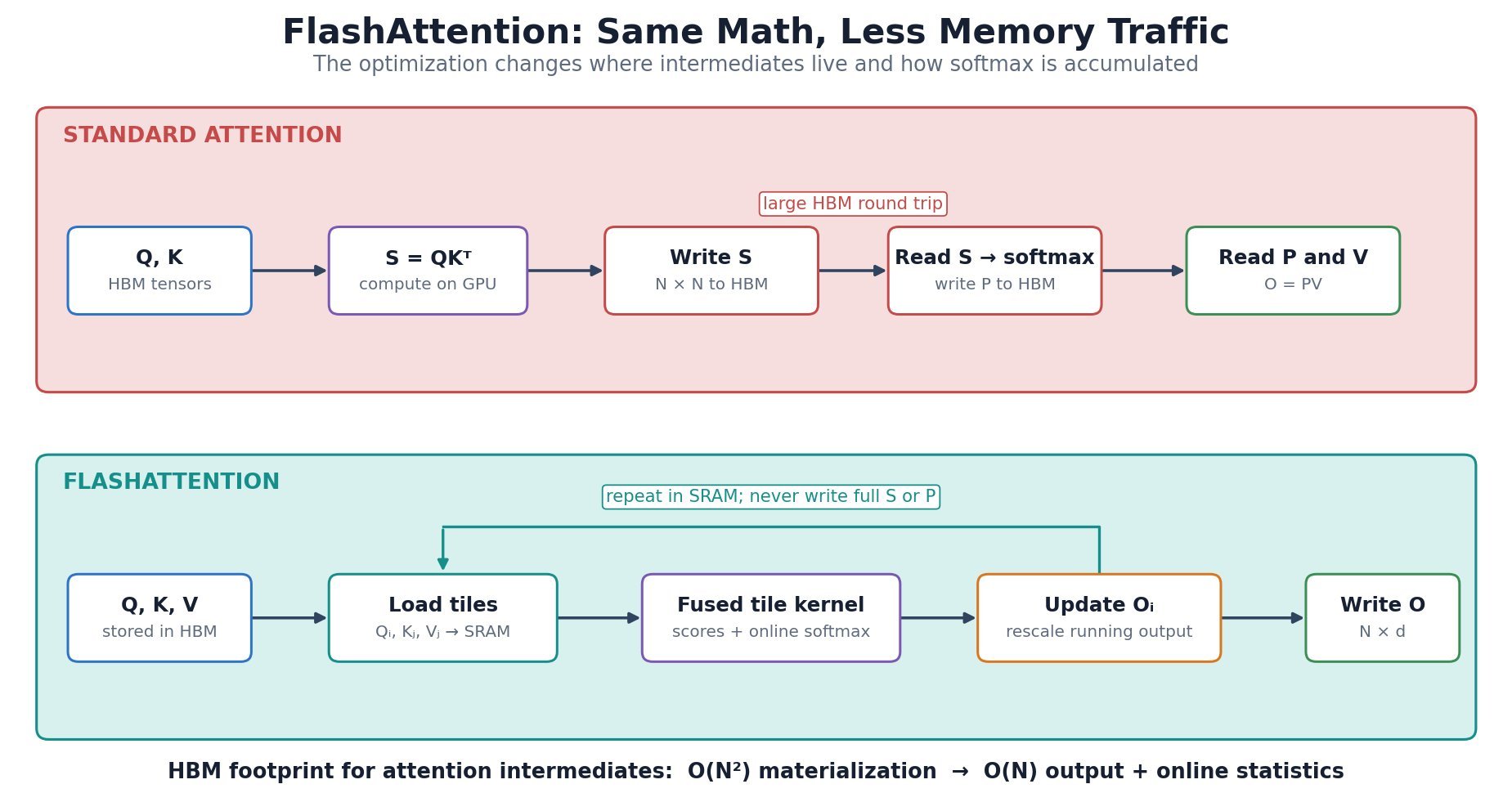
 tile to update the output without retaining previous score blocks.
tile to update the output without retaining previous score blocks.

 is the scaled score between query row
is the scaled score between query row  and key row
and key row  , with head width
, with head width  .
. is the running row maximum after tile
is the running row maximum after tile  .
. is the running softmax denominator, initialized with
is the running softmax denominator, initialized with  ; the exponential factors rescale earlier partial sums when the maximum changes.
; the exponential factors rescale earlier partial sums when the maximum changes.
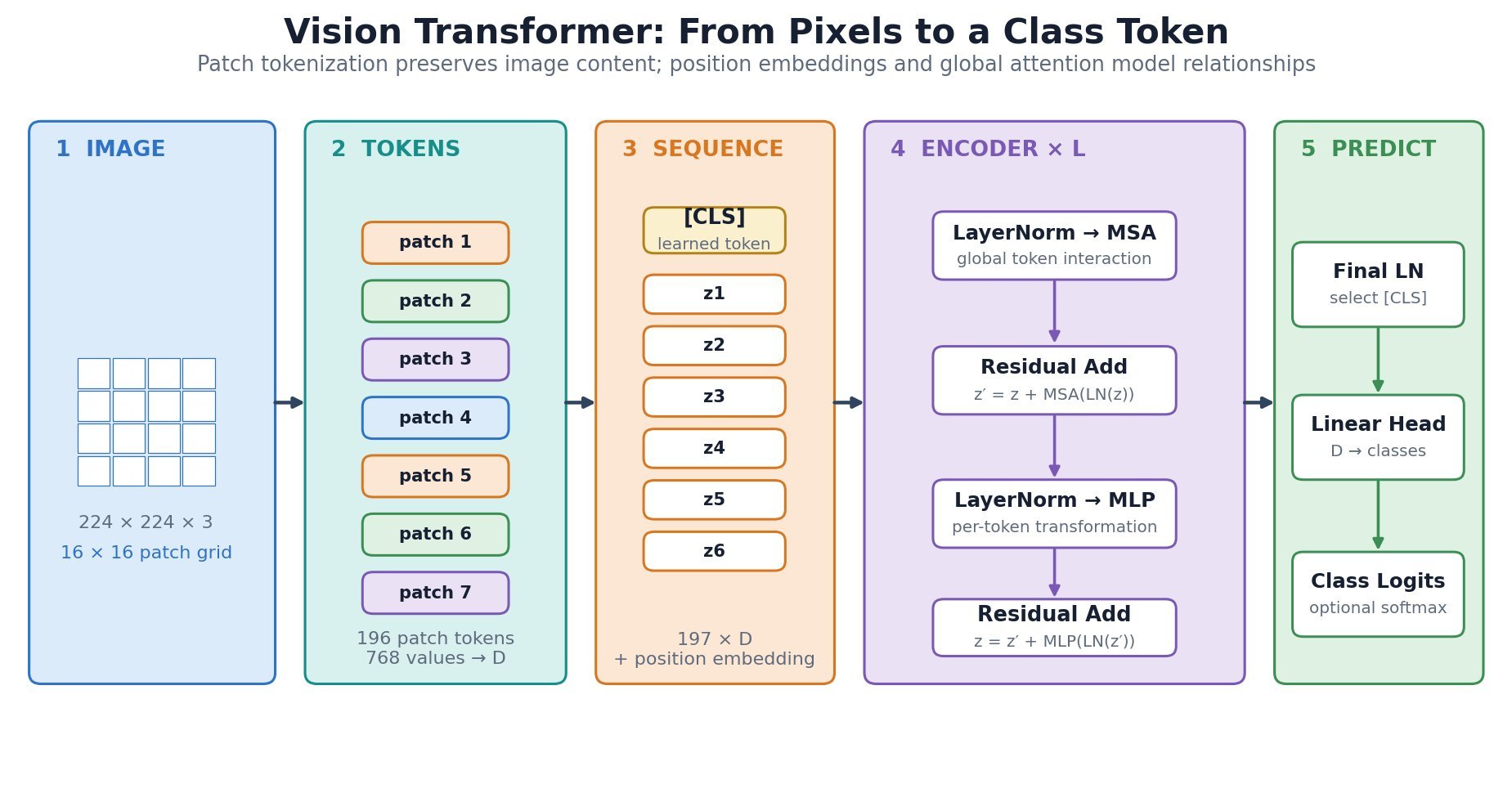
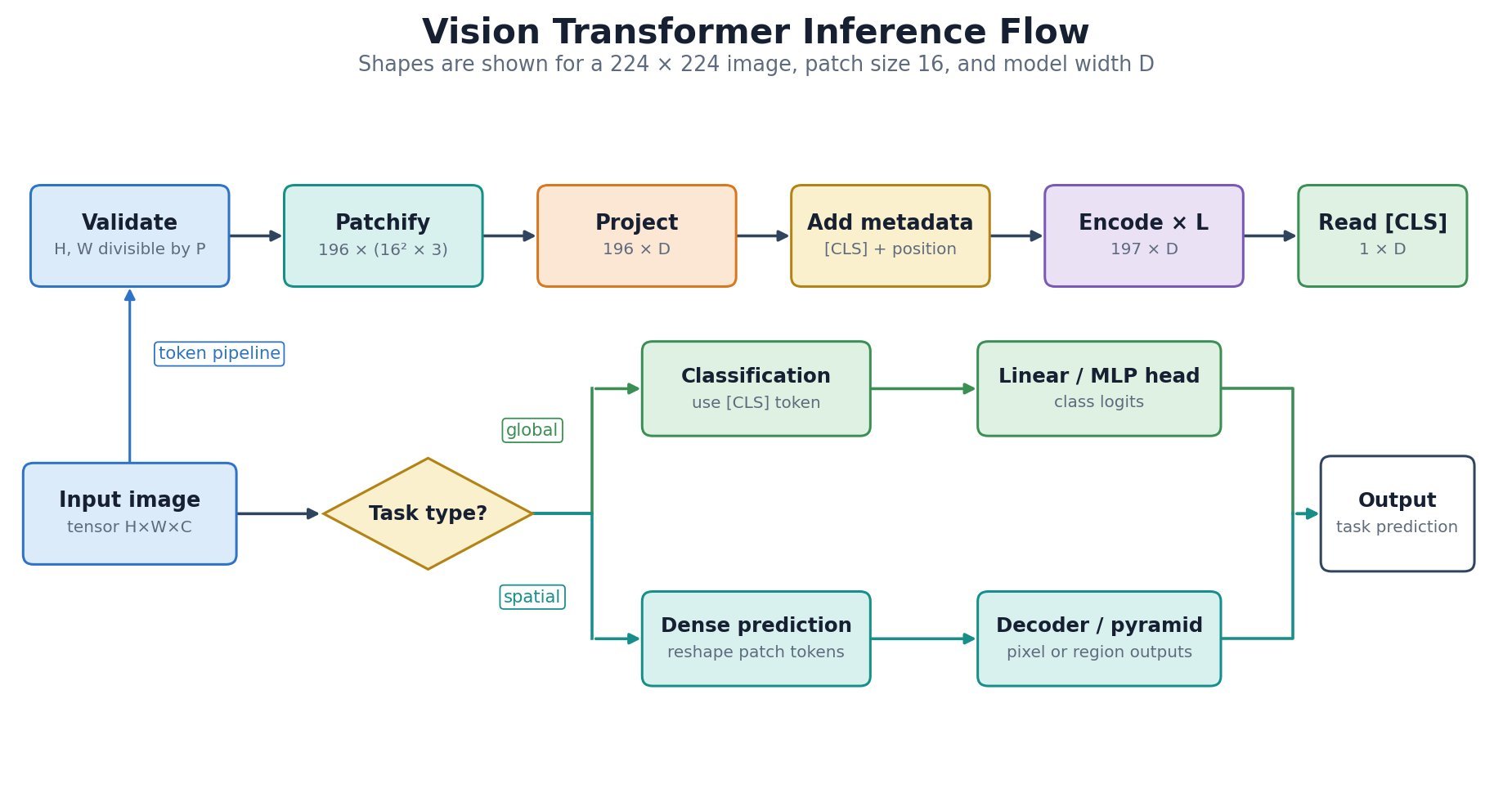
 is divided into
is divided into  non-overlapping
non-overlapping  patches; each flattened patch is projected to width
patches; each flattened patch is projected to width  .
.
![z_0=[x_{\mathrm{cls}};x_p^1E;x_p^2E;\ldots;x_p^NE]+E_{\mathrm{pos}}](https://s0.wp.com/latex.php?latex=z_0%3D%5Bx_%7B%5Cmathrm%7Bcls%7D%7D%3Bx_p%5E1E%3Bx_p%5E2E%3B%5Cldots%3Bx_p%5ENE%5D%2BE_%7B%5Cmathrm%7Bpos%7D%7D&bg=ffffff&fg=000&s=3&c=20201002)

 is the initial token sequence supplied to the Transformer encoder.
is the initial token sequence supplied to the Transformer encoder. is the learned class token, and
is the learned class token, and  is flattened image patch
is flattened image patch  projects each
projects each  patch to width
patch to width  supplies positional embeddings.
supplies positional embeddings. is the per-head query/key width.
is the per-head query/key width. to
to  where K is a small constant (typically 4). This makes it ideal for high-resolution feature maps in object detection where full attention is computationally prohibitive — for a 1024×1024 feature map, standard attention requires ~1M operations per head while deformable attention needs only ~4K.
where K is a small constant (typically 4). This makes it ideal for high-resolution feature maps in object detection where full attention is computationally prohibitive — for a 1024×1024 feature map, standard attention requires ~1M operations per head while deformable attention needs only ~4K.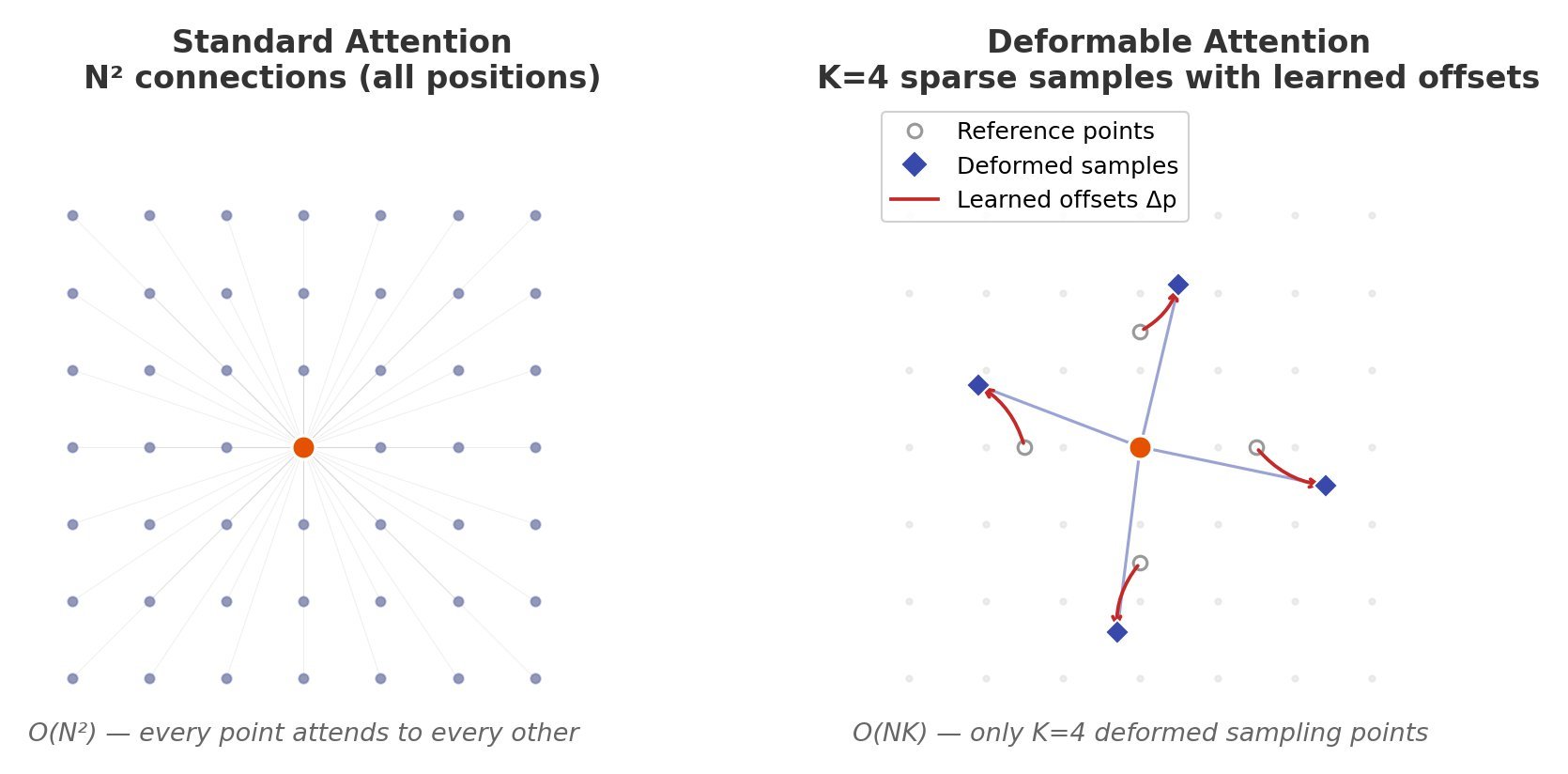
 positions, deformable attention samples only K reference points per query, typically K=4 or 8, reducing the key-value set from N to K.
positions, deformable attention samples only K reference points per query, typically K=4 or 8, reducing the key-value set from N to K. offsets from each reference point
offsets from each reference point  using a lightweight linear layer on query features, requiring only
using a lightweight linear layer on query features, requiring only  additional computation where C is channel dimension.
additional computation where C is channel dimension.
![y(p) = \sum_{m=1}^{M} W_m \left[ \sum_{k=1}^{K} A_{mk} \cdot W_m' x(p + p_k + \Delta p_{mk}) \right]](https://s0.wp.com/latex.php?latex=y%28p%29+%3D+%5Csum_%7Bm%3D1%7D%5E%7BM%7D+W_m+%5Cleft%5B+%5Csum_%7Bk%3D1%7D%5E%7BK%7D+A_%7Bmk%7D+%5Ccdot+W_m%27+x%28p+%2B+p_k+%2B+%5CDelta+p_%7Bmk%7D%29+%5Cright%5D&bg=ffffff&fg=000&s=3&c=20201002)
 is the reference position (query location on the feature map)
is the reference position (query location on the feature map) is the number of attention heads
is the number of attention heads is the number of sampled keys per head (typically 4)
is the number of sampled keys per head (typically 4) are fixed reference offsets (uniformly initialized)
are fixed reference offsets (uniformly initialized) are learned deformable offsets (2D, predicted per head per key)
are learned deformable offsets (2D, predicted per head per key) is the attention weight (normalized, not from softmax over all positions)
is the attention weight (normalized, not from softmax over all positions) are projection matrices for each head
are projection matrices for each head , where
, where  . The attention weights
. The attention weights  are computed via a separate softmax over only K elements, not the full N positions. In Deformable DETR, multi-scale deformable attention extends this to sample across multiple feature map resolutions simultaneously, enabling the model to capture both small and large objects efficiently.
are computed via a separate softmax over only K elements, not the full N positions. In Deformable DETR, multi-scale deformable attention extends this to sample across multiple feature map resolutions simultaneously, enabling the model to capture both small and large objects efficiently.
 is multiplied by a sigmoid gate
is multiplied by a sigmoid gate  where
where  is a head-specific projection.
is a head-specific projection.![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000&s=2&c=20201002) , and empirical measurements show mean gate activation of ~0.116, meaning most heads are heavily suppressed — introducing beneficial sparsity without hard pruning.
, and empirical measurements show mean gate activation of ~0.116, meaning most heads are heavily suppressed — introducing beneficial sparsity without hard pruning.


 is the output of the
is the output of the ![g_i \in [0, 1]](https://s0.wp.com/latex.php?latex=+g_i+%5Cin+%5B0%2C+1%5D+&bg=ffffff&fg=000&s=2&c=20201002) is the head-specific gate score
is the head-specific gate score is a learned projection from query to scalar gate
is a learned projection from query to scalar gate is the sigmoid function
is the sigmoid function denotes element-wise multiplication
denotes element-wise multiplication is the standard output projection
is the standard output projection adds only
adds only  parameters per head — a negligible overhead of ~0.1% of total model parameters — yet significantly improves long-context performance. On the RULER benchmark at 128K context length, gated attention improves needle-in-haystack retrieval accuracy from ~72% to ~94% compared to standard attention.
parameters per head — a negligible overhead of ~0.1% of total model parameters — yet significantly improves long-context performance. On the RULER benchmark at 128K context length, gated attention improves needle-in-haystack retrieval accuracy from ~72% to ~94% compared to standard attention.
 represents the absolute position of the token in the sequence.
represents the absolute position of the token in the sequence.  represents the base frequency/rotation angle.
represents the base frequency/rotation angle.  represent the components of the embedding vector.
represent the components of the embedding vector.
 →
→  ) before reducing it back?
) before reducing it back? ) to enhance the model’s ability to learn complex, non-linear feature interactions, then reduces it back to maintain compatibility with other layers. This design acts as a bottleneck, balancing expressiveness and efficiency, and has been empirically shown to boost performance in large-scale models.
) to enhance the model’s ability to learn complex, non-linear feature interactions, then reduces it back to maintain compatibility with other layers. This design acts as a bottleneck, balancing expressiveness and efficiency, and has been empirically shown to boost performance in large-scale models. allows the FFN to capture richer nonlinear transformations.
allows the FFN to capture richer nonlinear transformations.
 is the input vector.
is the input vector. expands the dimension.
expands the dimension. projects back down.
projects back down.