What distinguishes self-attention from cross-attention in transformer models?
Answer
Self-attention allows a sequence to attend to itself, making it powerful for capturing intra-sequence relationships. Cross-attention bridges different sequences, crucial for combining encoder and decoder representations in tasks like machine translation.
Input Scope:
Self-Attention: Query, key, and value all come from the same input sequence
Cross-Attention: Query comes from one sequence, key and value come from a different source
Usage in Transformer Architecture:
Self-Attention: Used in both the encoder and decoder for modeling internal dependencies
Cross-Attention: Used in the decoder to integrate the encoder output
Both mechanisms use the scaled dot-product attention formula:
Where: ,
,  , and
, and  represent query, key, and value matrices, respectively
represent query, key, and value matrices, respectively is the dimensionality of the key vectors
is the dimensionality of the key vectors
The plot below on the left demonstrates self-attention by showing a token’s attention to all other tokens within the same sequence. The plot below on the right illustrates cross-attention, where tokens from one sequence (the decoder) attend to tokens from another, separate sequence (the encoder).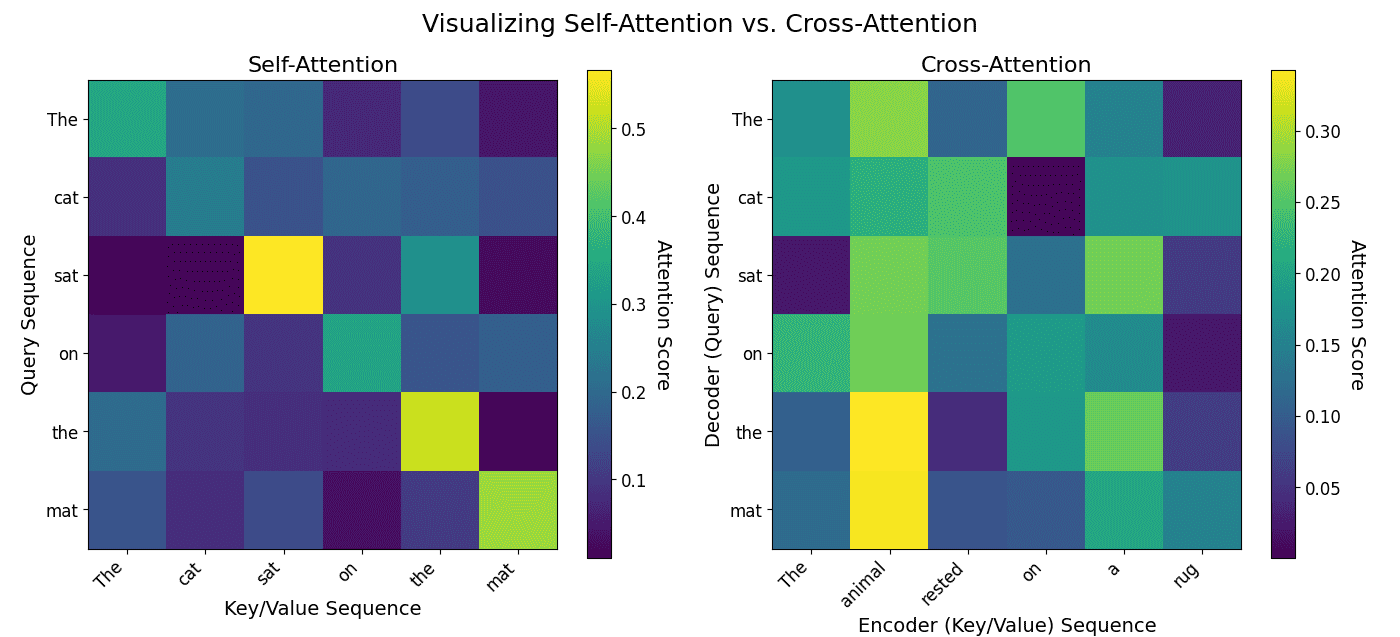
Leave a Reply