How does the random forest algorithm operate? Please outline its key steps.
Answer
Random Forest builds an ensemble of decision trees using bootstrapped samples and random feature subsets at each split. This combination reduces variance, combats overfitting, and improves predictive accuracy. The final output aggregates the predictions of all trees (majority vote for classification, averaging for regression).
(1) Bootstrap Sampling: Create multiple subsets of the original training data by sampling with replacement (bootstrap samples).
(2) Grow Decision Trees: For each bootstrap sample, train an unpruned decision tree.
(3) Random Feature Selection: At each split in a tree, randomly select a subset of features. The split is chosen only among this random subset (increases diversity).
(4) Aggregate Results with Voting or Averaging:
Classification: Each tree votes for a class label. The majority vote is used.
Where: = prediction of the b-th tree.
= prediction of the b-th tree. = total number of trees.
= total number of trees.
Regression: Each tree predicts a numeric value. The average is used.
Where: = prediction of the b-th tree. = total number of trees.
The example below shows the decision boundary differences between three decision trees and their random forest ensemble.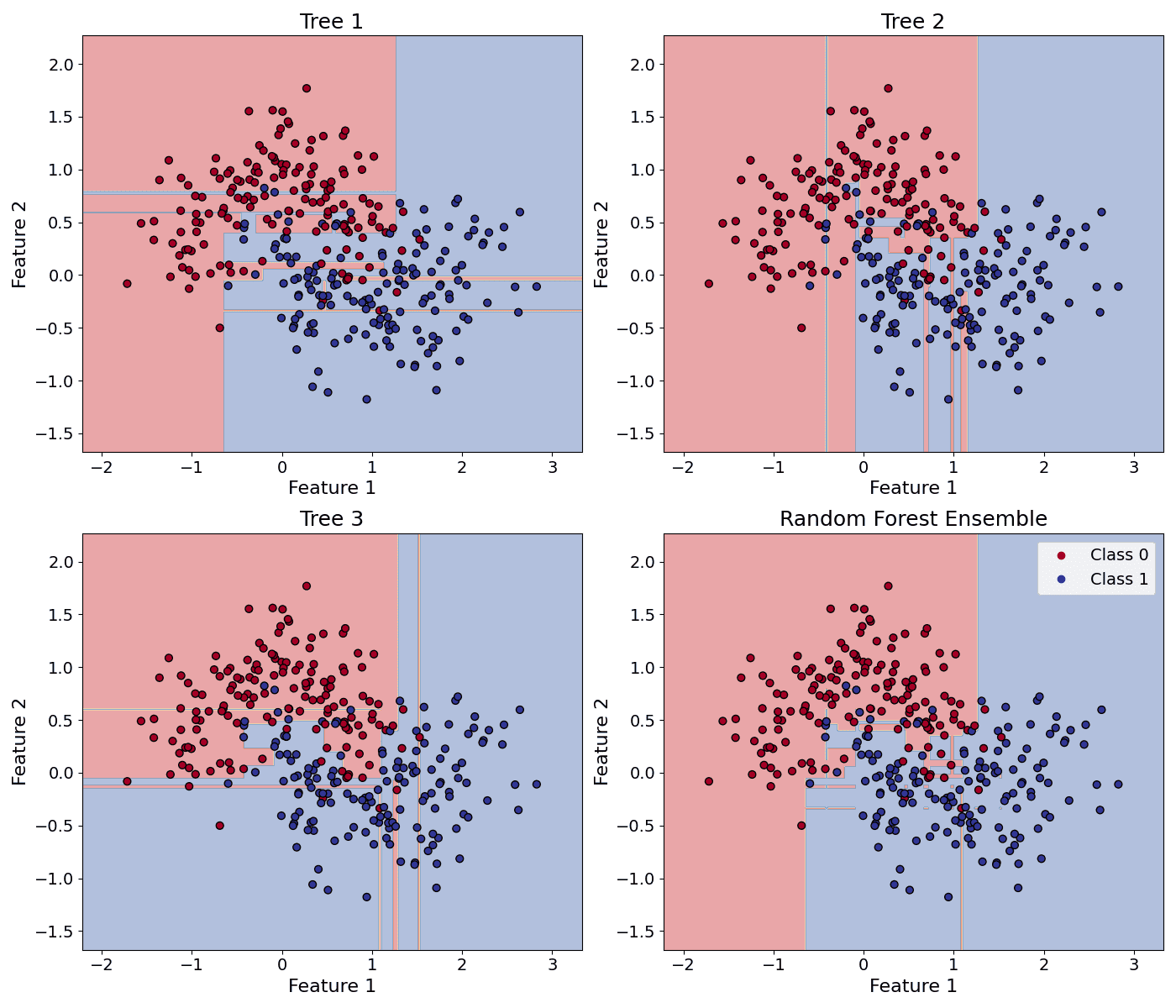
Leave a Reply