What is Learning Rate Warmup? What is the purpose of using Learning Rate Warmup?
Answer
Learning Rate Warmup is a training technique where the learning rate starts from a small value and gradually increases to a target (base) learning rate over the first few steps or epochs of training.
Purpose of Using Learning Rate Warmup:
(1) Stabilizes Early Training: At the beginning of training, weights are randomly initialized, making the model sensitive to large updates. A warmup gradually increases the learning rate, preventing unstable behavior.
(2) Allow Optimizers to Adapt: Optimizers like Adam and AdamW rely on gradient statistics that can be unstable at the start. Warmup allows these optimizers to accumulate more accurate estimates before using a high learning rate.
(3) Enables Large Batch Training: Mitigates issues that can arise when combining a large batch size with a high initial learning rate.
Below shows an example using Learning Warmup followed by Cosine Decay.

 represents an individual feature value in the batch.
represents an individual feature value in the batch. represents the mean of that feature across the current batch.
represents the mean of that feature across the current batch. represents the variance of that feature across the current batch.
represents the variance of that feature across the current batch.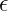 is a small constant (e.g.
is a small constant (e.g.  ) added to the denominator for numerical stability.
) added to the denominator for numerical stability. 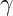 is a learnable scaling parameter.
is a learnable scaling parameter. is a learnable shifting parameter.
is a learnable shifting parameter.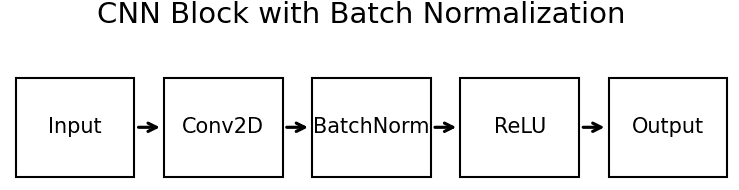
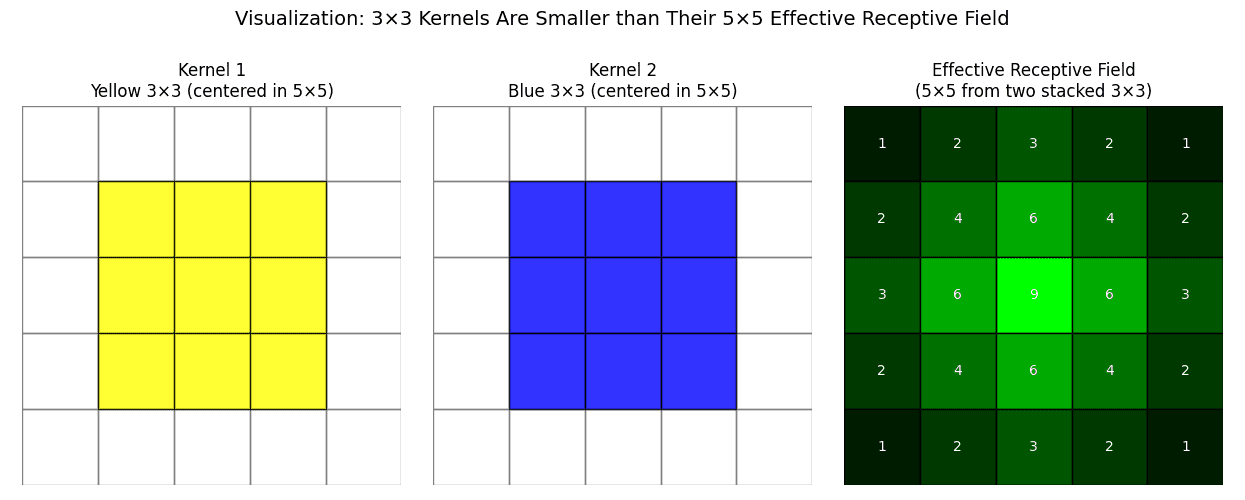
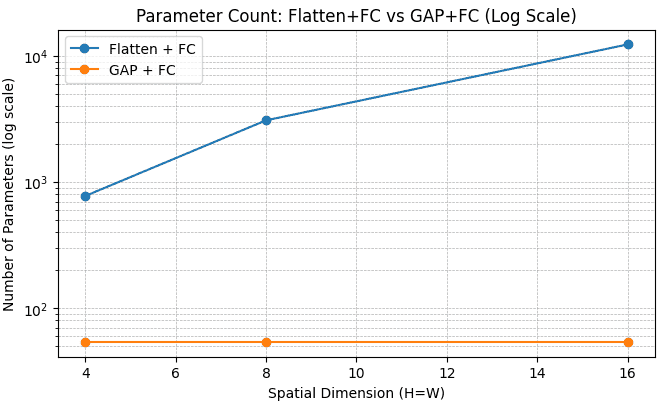
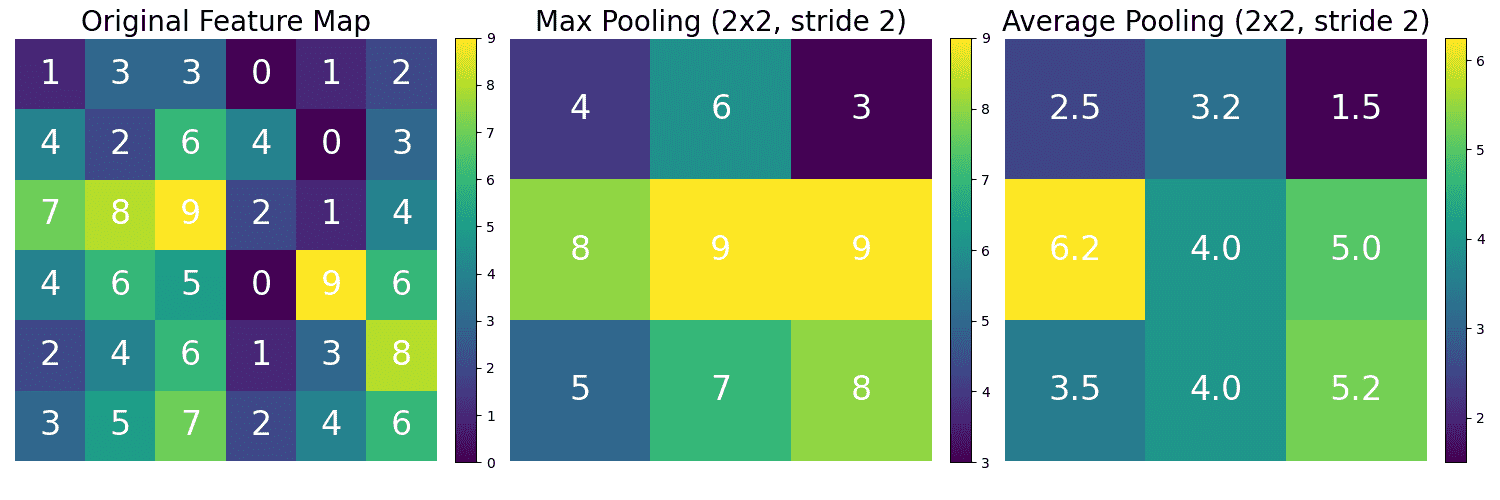
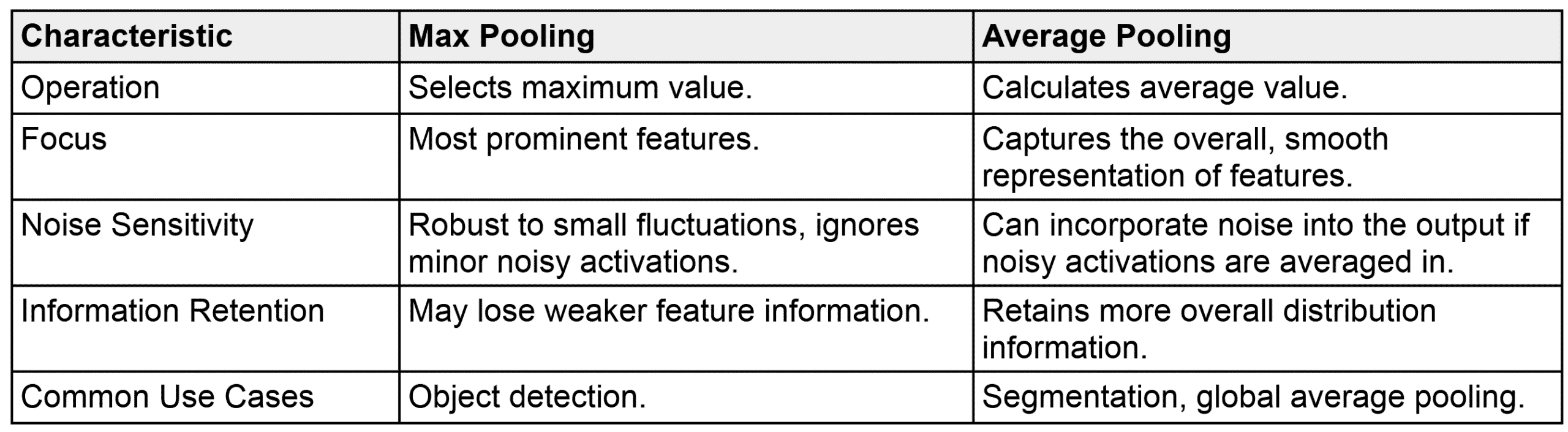
 total parameters) have the same receptive field as a 5×5 layer (
total parameters) have the same receptive field as a 5×5 layer ( total parameters) but fewer parameters.
total parameters) but fewer parameters.