Please explain the benefits and drawbacks of random forest.
Answer
Random Forest is a powerful ensemble method that reduces overfitting and improves predictive accuracy by combining many decision trees. However, it trades interpretability and computational efficiency for these benefits and may require careful tuning when dealing with large, imbalanced, or sparse datasets.
Benefits of random forest:
(1) Reduces Overfitting: Aggregating many trees lowers variance.
(2) Robust to Noise and Outliers: Less sensitive to anomalous data.
(3) Handles High Dimensionality: Works well with many input features.
(4) Estimates Feature Importance: Helps identify influential variables.
(5) Built-in Bagging: Bootstrap sampling improves generalization.
Drawbacks of random forest:
(1) Less Interpretability: Hard to visualize or explain compared to a single decision tree.
(2) Computational Cost: Training and prediction can be slower with many trees.
(3) Memory Usage: Large forests can consume significant resources.
(4) Biased with Imbalanced Data: Class imbalance can lead to biased predictions.
(5) Not Always Optimal for Sparse Data: May underperform compared to other algorithms on very sparse datasets.
The example below demonstrates that the random forest sometimes underperforms on the imbalanced dataset.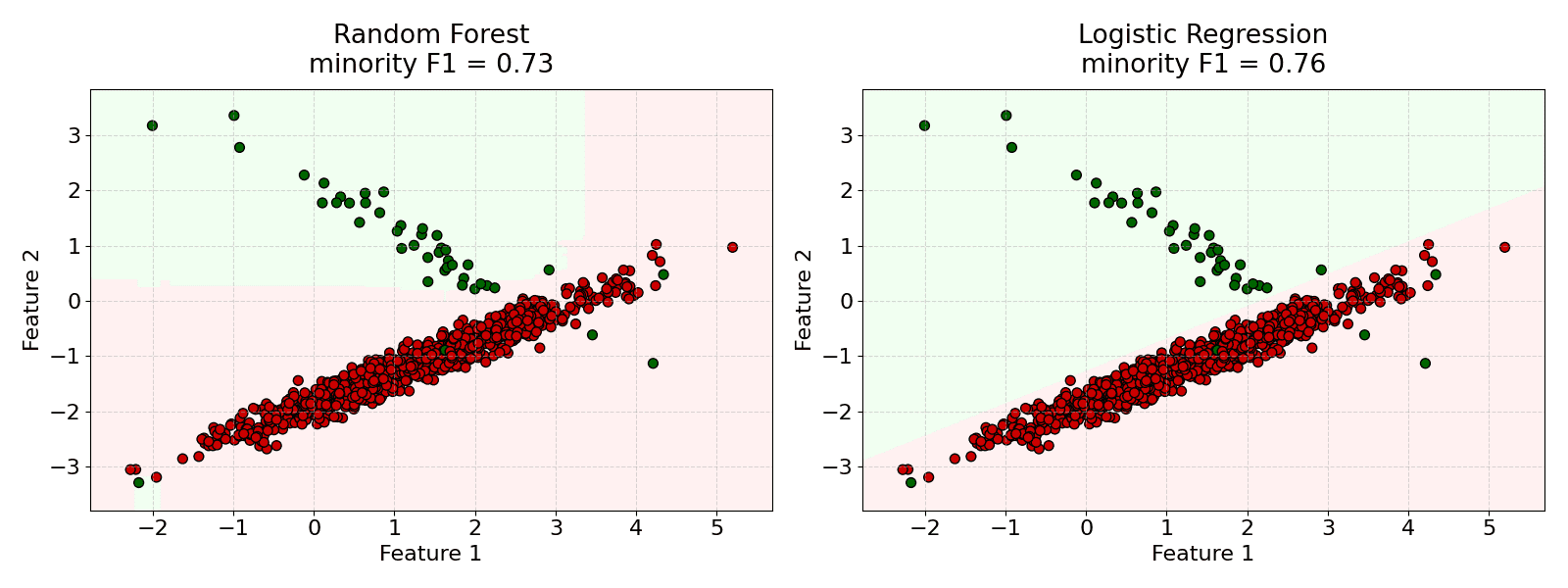
 in K-Means, use the visual plot like the elbow method, quantitative metrics like the silhouette score, or statistical methods like the gap statistic. These help balance model fit and generalization without overfitting.
in K-Means, use the visual plot like the elbow method, quantitative metrics like the silhouette score, or statistical methods like the gap statistic. These help balance model fit and generalization without overfitting.
 is cluster
is cluster  ,
,  is its centroid.
is its centroid.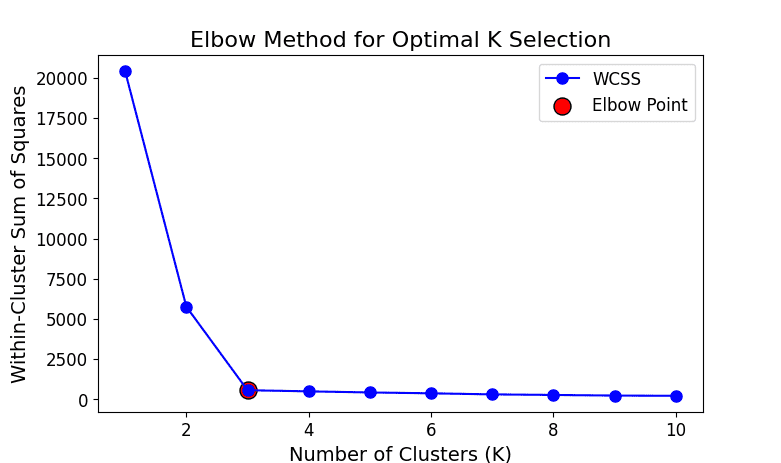
 can be calculated by the following equation.
can be calculated by the following equation.
 = intra-cluster distance,
= intra-cluster distance, = nearest-cluster distance.
= nearest-cluster distance. uniformly at random from the dataset.
uniformly at random from the dataset. , compute its squared distance to the nearest chosen centroid:
, compute its squared distance to the nearest chosen centroid:
 is one of the already chosen centroids.
is one of the already chosen centroids. with probability:
with probability:
 is the squared distance from point
is the squared distance from point  is the sum of minimum squared distances from all data points to their nearest chosen centroid.
is the sum of minimum squared distances from all data points to their nearest chosen centroid.

 is the actual outcome for the i‑th instance.
is the actual outcome for the i‑th instance. represents the predicted value using
represents the predicted value using  is the total number of validation samples.
is the total number of validation samples. is a loss function.
is a loss function.

 are input vectors.
are input vectors. controls the scale of the inner product.
controls the scale of the inner product. is a constant that controls the influence of higher-order terms.
is a constant that controls the influence of higher-order terms. is the degree of the polynomial.
is the degree of the polynomial.
 is the squared Euclidean distance between the vectors.
is the squared Euclidean distance between the vectors. is a parameter that controls the width of the Gaussian (spread).
is a parameter that controls the width of the Gaussian (spread).
 is a bias term.
is a bias term.





 is set to approximately 1.0507 (greater than 1). This means in the positive regime, each layer effectively amplifies the gradient by a factor of
is set to approximately 1.0507 (greater than 1). This means in the positive regime, each layer effectively amplifies the gradient by a factor of