Can you explain how the Adam optimizer works?
Answer
The Adam (Adaptive Moment Estimation) optimizer is a powerful algorithm for training deep learning models, combining the principles of Momentum and RMSprop to compute adaptive learning rates for each parameter.
Adam updates following the steps below:
(1) First Moment Calculation(Mean/Momentum)
It computes an exponentially decaying average of past gradients, which is the estimate of the first moment (mean) of the gradient. This introduces a momentum effect to smooth out the updates.
Where: is the 1st moment (mean of gradients).
is the 1st moment (mean of gradients). is the gradient at step
is the gradient at step  .
. controls momentum (default: 0.9).
controls momentum (default: 0.9).
(2) Second Moment Calculation (Variance)
Adam also computes an exponentially decaying average of past squared gradients, which is the estimate of the second moment (uncentered variance) of the gradient. This provides a measure of the scale (magnitude) of the gradients.
Where: is the 2nd moment (variance of gradients).
is the 2nd moment (variance of gradients). controls smoothing of squared gradients (default: 0.999).
controls smoothing of squared gradients (default: 0.999).
(3) Bias Correction
Since and are initialized as zero vectors, they are biased towards zero, especially during the initial steps. Adam applies bias correction to these estimates.

Where is the bias-corrected 1st moment.
is the bias-corrected 1st moment. is the bias-corrected 2nd moment.
is the bias-corrected 2nd moment. ,
,  are the exponential decay raised to step , correcting bias from initialization.
are the exponential decay raised to step , correcting bias from initialization.
(4) Parameter Update
The final parameter update scales the bias-corrected first moment () by the overall learning rate ( ) and divides by the square root of the bias-corrected second moment ().
) and divides by the square root of the bias-corrected second moment ().
Where: are model parameters. is the learning rate.
are model parameters. is the learning rate.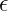 prevents division by zero.
prevents division by zero.
The plot below shows how the Adam optimizer efficiently moves from the starting point to the minimum of the quadratic bowl, taking adaptive steps that quickly converge to the origin.
Leave a Reply