What are the main differences between the encoder and decoder in a Transformer?
Answer
The encoder focuses on encoding input into rich representations via bidirectional self-attention, while the decoder leverages these for output generation through masked self-attention and cross-attention, ensuring autoregressive and context-aware predictions.
(1) Self‑Attention:
Encoder: Unmasked, attends to all positions in the input sequence.
Decoder: Masked, attends only to past positions to maintain causal order.
(2) Cross‑Attention:
Encoder: None.
Decoder: Present — attends to encoder outputs for context.
(3) Masking:
Encoder: No masking needed.
Decoder: Causal mask prevents looking ahead.
(4) Positional Encoding:
Encoder: Added to source embeddings.
Decoder: Added to target embeddings (shifted right during training).
(5) Function:
Encoder: Encodes the full source sequence into contextual representations.
Decoder: Generates the target sequence one token at a time using its own history and encoder context.
The figure below shows the encoder and the decoder in the Transformer.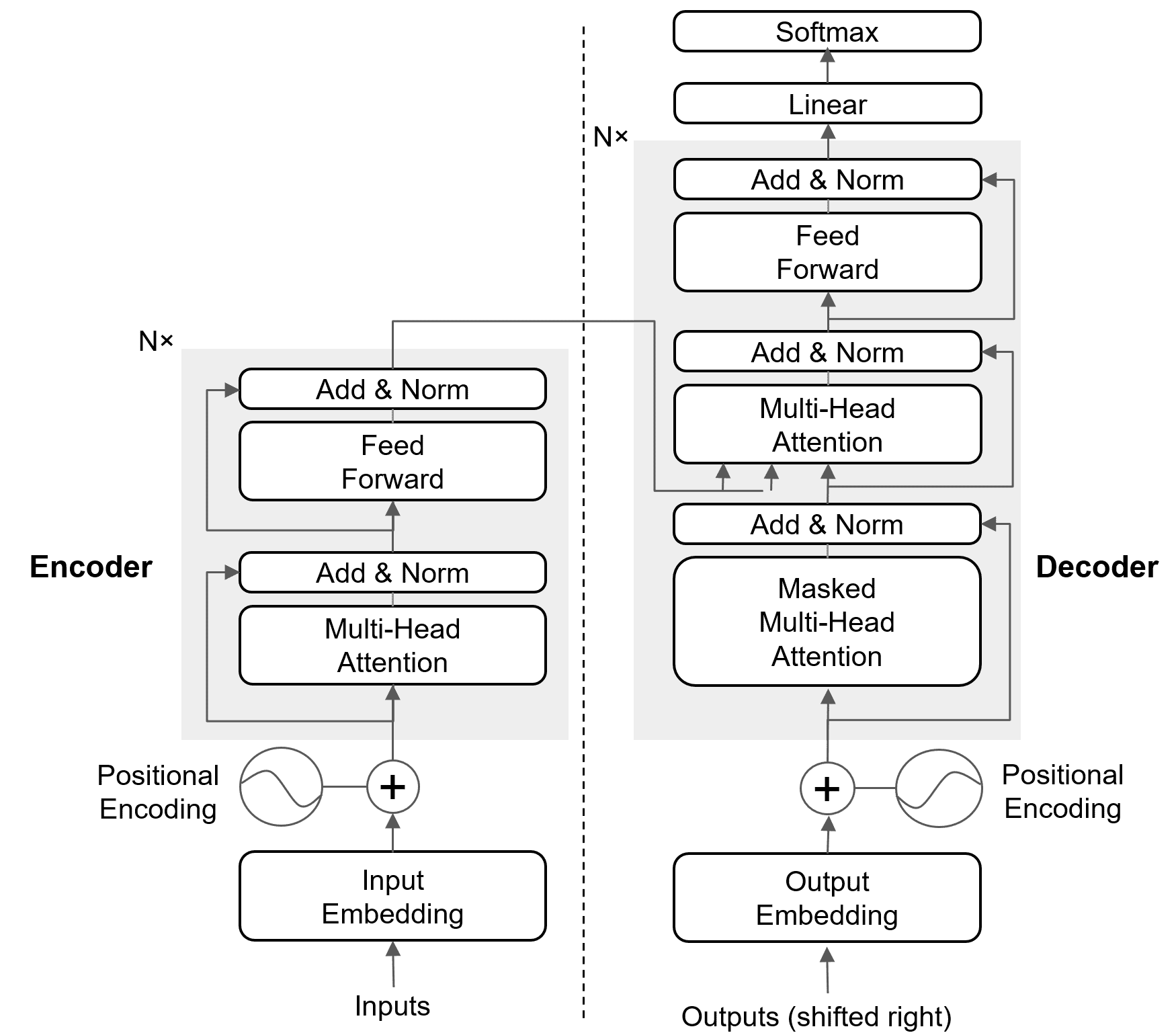
Leave a Reply