What is KV Cache in transformers, and why is it useful during inference?
Answer
The KV Cache in transformers optimizes inference by storing and reusing key and value vectors from the attention mechanism, avoiding redundant computations for previous tokens in a sequence. This is particularly useful in autoregressive models, where each new token requires attention over all prior tokens. By caching K and V vectors, the model only computes the query for the new token and retrieves cached K and V for earlier tokens, improving speed at the cost of higher memory usage.
The attention mechanism, optimized by KV Cache, is:
Where: = query of the current token t.
= query of the current token t. = cached keys and values for all tokens up to t.
= cached keys and values for all tokens up to t. = key dimension.
= key dimension.
The figure below explains the KV cache in autoregressive transformers.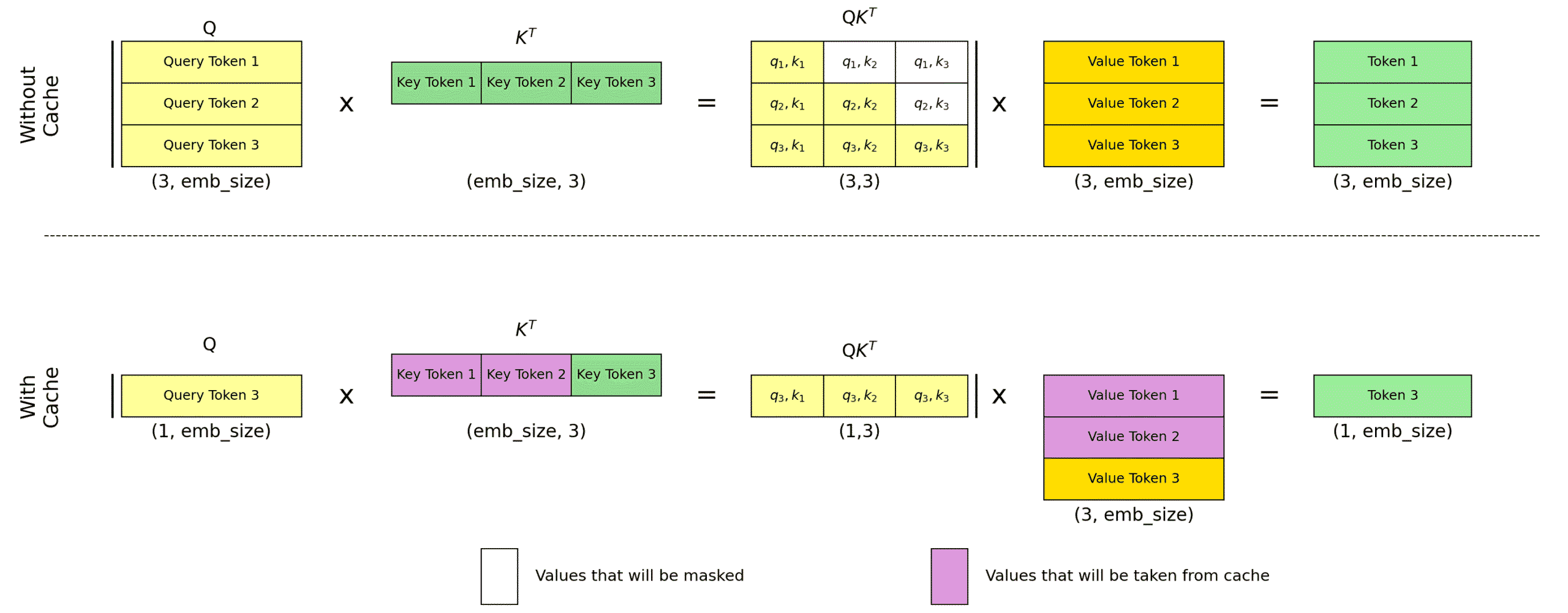
Leave a Reply