Describe the process and benefits of knowledge distillation.
Answer
Knowledge Distillation (KD) transfers “dark knowledge” about inter-class relationships from a large, accurate teacher model to a smaller student model. The student learns via a temperature-scaled softmax and a combined distillation plus supervised loss, enabling substantial model compression and faster inference while retaining high accuracy, provided that the teacher quality, student capacity, and hyperparameters are well chosen.
Definition: Knowledge distillation is a process where a smaller model (student) learns to mimic the behavior of a larger, well-trained model (teacher).
Soft Targets: The student is trained not only on hard labels (one-hot) but also on the soft output probabilities of the teacher.
Temperature Scaling: Teacher logits are softened using a temperature  to reveal more information about class similarities:
to reveal more information about class similarities:
Where: : Raw score (logit) for the i-th class.
: Raw score (logit) for the i-th class. : Total number of classes in the classification problem.
: Total number of classes in the classification problem. : Temperature parameter (>0) used to soften the probabilities. Higher produces a smoother distribution, revealing relationships between classes (“dark knowledge”).
: Temperature parameter (>0) used to soften the probabilities. Higher produces a smoother distribution, revealing relationships between classes (“dark knowledge”).
The below plot shows the Softmax probabilities for a fixed set of Teacher logits under three different temperatures. Increasing the temperature smooths the distribution.
Loss Function: Typically combines distillation loss (difference between teacher and student soft outputs) and standard cross-entropy loss with true labels.
Key Benefits of KD:
(1) Model compression: the student is smaller and faster while retaining much of the teacher’s performance, enabling deployment on resource-constrained devices.
(2) Inference Speed: Significantly decreases latency, making the model suitable for deployment on edge devices or real-time applications.
(3) Improved Generalization: The Teacher’s smooth soft targets act as a form of powerful regularization, often leading the Student to generalize better than if it were trained only on hard labels.
The plot below demonstrates the Knowledge Distillation (KD) process.


 = number of input units
= number of input units = number of output units
= number of output units means weights are sampled from a normal (Gaussian) distribution with mean
means weights are sampled from a normal (Gaussian) distribution with mean  and variance
and variance  .
. means weights are sampled from a uniform distribution in the range
means weights are sampled from a uniform distribution in the range ![[a, b]](https://s0.wp.com/latex.php?latex=+%5Ba%2C+b%5D+&bg=ffffff&fg=000&s=2&c=20201002) .
.



 is the 1st moment (mean of gradients).
is the 1st moment (mean of gradients). is the gradient at step
is the gradient at step  .
. controls momentum (default: 0.9).
controls momentum (default: 0.9).
 is the 2nd moment (variance of gradients).
is the 2nd moment (variance of gradients). controls smoothing of squared gradients (default: 0.999).
controls smoothing of squared gradients (default: 0.999).

 is the bias-corrected 1st moment.
is the bias-corrected 1st moment. is the bias-corrected 2nd moment.
is the bias-corrected 2nd moment. ,
,  are the exponential decay raised to step
are the exponential decay raised to step  ) and divides by the square root of the bias-corrected second moment (
) and divides by the square root of the bias-corrected second moment (
 are model parameters.
are model parameters.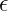 prevents division by zero.
prevents division by zero.



 is the input feature vector,
is the input feature vector, is the weight vector, and
is the weight vector, and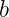 is the bias term.
is the bias term.

