How does multi-head attention work in transformer architectures?
Answer
Multi-head attention projects the input into multiple distinct subspaces, with each head performing scaled dot-product attention independently on the full input sequence. By attending to different aspects or relationships within the data, these separate heads capture diverse information patterns. Their outputs are then combined to form a richer, more expressive representation, enabling the model to understand complex dependencies better and improve overall performance.
Outputs from all heads are concatenated and linearly projected to form the final output.
All heads are computed in parallel, enabling efficient computation.
Where:

 : Final output projection matrix that maps the concatenated attention outputs back to the original model dimension.
: Final output projection matrix that maps the concatenated attention outputs back to the original model dimension. : Number of attention heads.
: Number of attention heads. : Dimensionality of the input embeddings and final output.
: Dimensionality of the input embeddings and final output. : Dimension of each head’s projected subspace.
: Dimension of each head’s projected subspace.
The below figure shows a single-head attention heatmap and 4 independent multi-head attention heatmaps.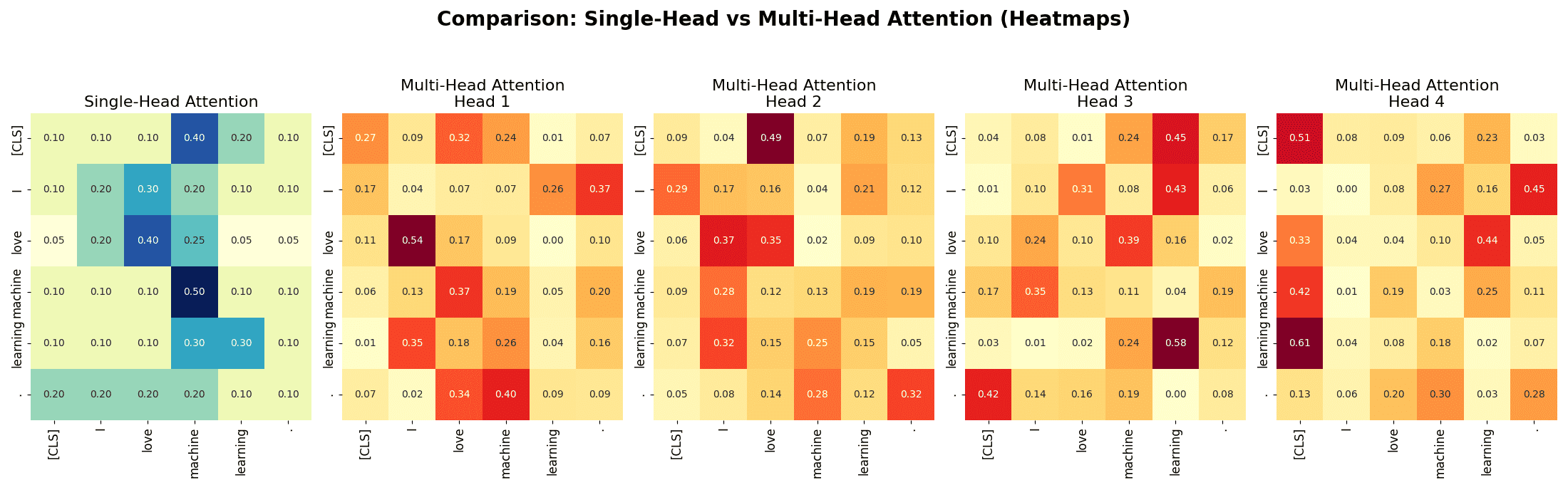
Leave a Reply