Which activation functions do transformer models use?
Answer
Transformers mainly use GELU/ReLU in the feed-forward layers to introduce non-linearity and Softmax in attention to produce normalized attention weights. GELU is preferred for smoother gradient flow and better performance.
(1) Feed-Forward Network (FFN):
Uses ReLU or GELU as the non-linear activation.
GELU is more common in modern Transformers (like BERT, GPT).
Equation for GELU:![\mbox{GELU}(x) = x \cdot \Phi(x) = x \cdot \frac{1}{2}\left[1 + \mbox{erf}\left(\frac{x}{\sqrt{2}}\right)\right]](https://s0.wp.com/latex.php?latex=%5Cmbox%7BGELU%7D%28x%29+%3D+x+%5Ccdot+%5CPhi%28x%29+%3D+x+%5Ccdot+%5Cfrac%7B1%7D%7B2%7D%5Cleft%5B1+%2B+%5Cmbox%7Berf%7D%5Cleft%28%5Cfrac%7Bx%7D%7B%5Csqrt%7B2%7D%7D%5Cright%29%5Cright%5D&bg=ffffff&fg=000&s=3&c=20201002)
Where: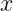 is the input,
is the input,  is the Cumulative Distribution Function (CDF) of the standard Gaussian.
is the Cumulative Distribution Function (CDF) of the standard Gaussian.
The figure below demonstrates the difference between ReLU and GELU.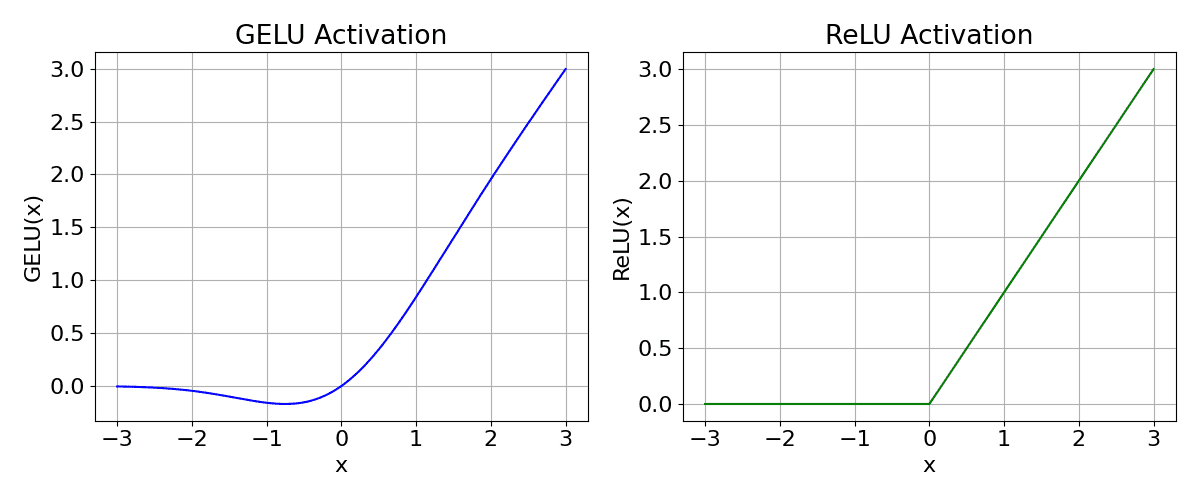
(2) Attention Output:
Uses Softmax to convert attention scores into probabilities.
Equation for Softmax:
Where: represents the raw attention score for the i-th token,
represents the raw attention score for the i-th token,  is the total number of tokens considered in attention.
is the total number of tokens considered in attention.
Leave a Reply