What is the role of masking in attention?
Answer
Masking is a critical technique in transformer attention mechanisms that controls which parts of the input sequence the model is allowed to focus on.
(1) Leakage prevention: Blocks access to future tokens in autoregressive decoding to preserve causality.
(2) Padding handling: Excludes pad positions so they don’t absorb probability mass or distort context.
(3) Structured constraint: Enforces task rules (e.g., graph neighborhoods, spans, or blocked regions).
Core equation with mask:
Where: query matrix.
query matrix. key matrix.
key matrix. value matrix.
value matrix. key dimensionality (for scaling).
key dimensionality (for scaling). mask matrix with 0 for allowed positions and large negative values (e.g., −∞) for disallowed positions.
mask matrix with 0 for allowed positions and large negative values (e.g., −∞) for disallowed positions.
The figure below shows three side-by-side heatmaps: a padding mask that disallows attending to padding tokens, a causal mask that enforces autoregressive decoding, and a structured mask that enforces local neighborhood constraint.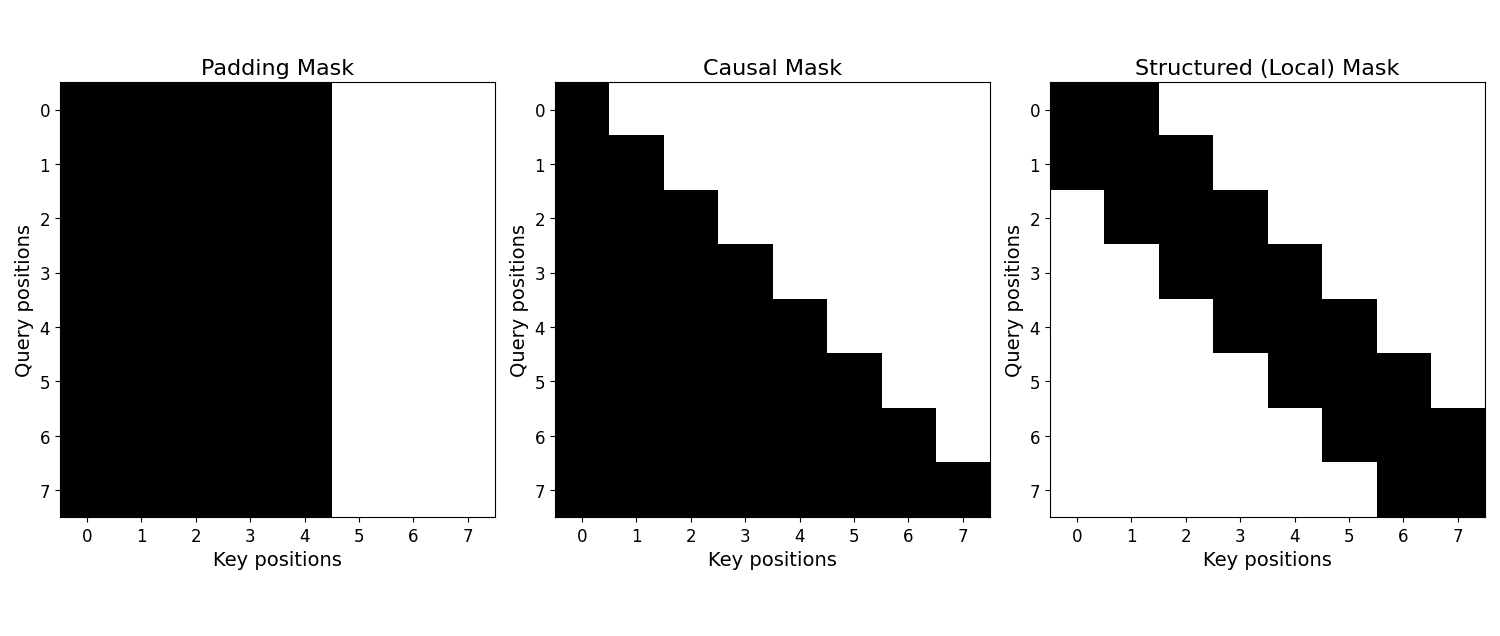
Leave a Reply