Walk me through the rationale behind Feature Scaling in machine learning.
Answer
Feature scaling is a fundamental data preprocessing step that normalizes or standardizes the range of numerical features. It is essential for many machine learning algorithms to ensure that all features contribute equally to the model, leading to faster convergence, improved accuracy, and better overall model performance, especially for algorithms sensitive to the magnitude of feature values or those based on distance calculations.
Definition: Process of normalizing or standardizing input features so they’re on a similar scale.
Why Needed: Many ML models (e.g., SVM, KNN) are sensitive to feature magnitude. Prevents dominant features from overpowering others due to scale.
Common Methods:
Min-Max Scaling: Scales features to a range (usually [0, 1]).
Where: represents the original value of the feature.
represents the original value of the feature. represents the minimum value of the feature in the dataset.
represents the minimum value of the feature in the dataset. represents the maximum value of the feature in the dataset.
represents the maximum value of the feature in the dataset.
Standardization (Z-score Normalization, centers data to mean 0, standard deviation to 1):
Where: represents the original value of the feature. represents the mean of the feature in the dataset.
represents the mean of the feature in the dataset. represents the standard deviation of the feature in the dataset.
represents the standard deviation of the feature in the dataset.
Below shows an example plot for original, min-max scaled, and standardized data.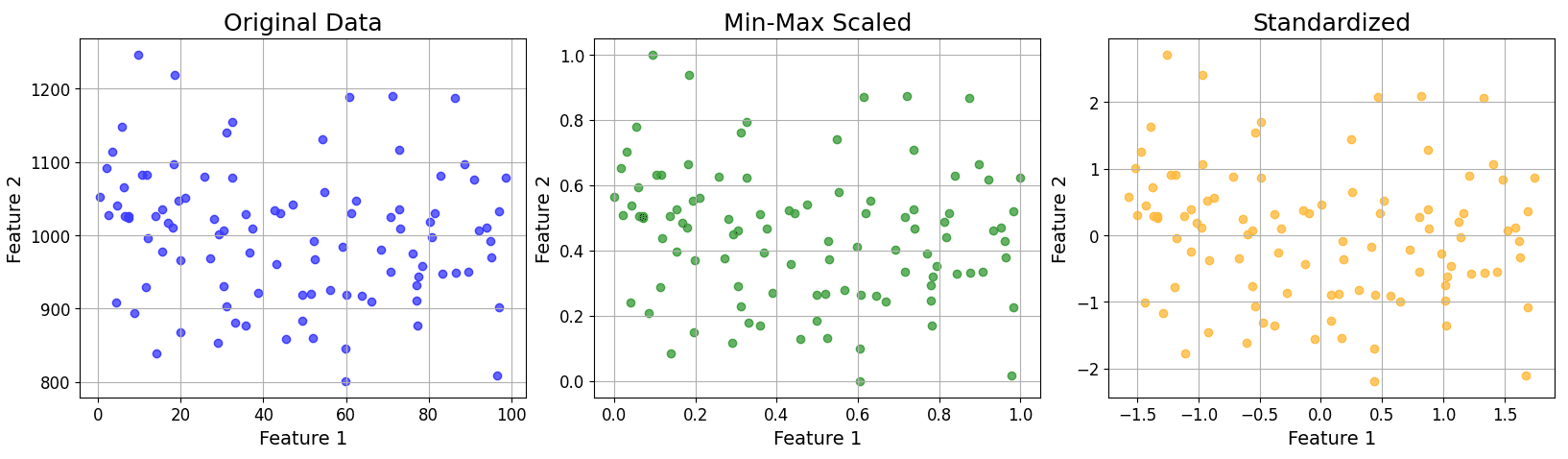
Leave a Reply