Backpropagation, backward propagation of errors, is the central algorithm by which multilayer neural networks learn. At its core, it efficiently computes how each weight and bias in the network contributes to the overall prediction error (loss). Then, it updates those parameters in the direction that reduces the error the most.
By combining the chain rule from calculus with gradient‑based optimization (e.g., gradient descent), backpropagation makes training deep architectures tractable and underpins virtually all modern advances in deep learning.
Steps to conduct Backpropagation:
(1) Forward Pass: Inputs are propagated through the network to compute outputs. Intermediate activations are stored for later use.
(2) Compute Loss: Use a loss function to compare the network’s output to the actual target values.
(3) Backward Pass (Error Propagation): The error is computed at the output layer. The chain rule is applied to recursively calculate the gradients of the loss for each weight, starting from the output layer back to the input layer.
(4) Gradient Calculation: For every neuron, determine how much its weights contributed to the error by computing partial derivatives.
(5) Update Weights: Adjust the weights using an optimization algorithm (e.g., gradient descent), by subtracting a fraction (learning rate) of the computed gradients. This step is repeated iteratively to gradually minimize the loss.
More details for step (3): Backward Pass (Error Propagation)
At the Output Layer:
Imagine a neuron with an output value  (its activation) and a weighted sum
(its activation) and a weighted sum  computed as:
computed as:

Suppose we use the mean squared error (MSE) as our loss function:

Where  is the target value.
is the target value.
The derivative of the loss to the activation is:

To update weights, we need to know how the loss changes to . Using the chain rule, we have:

For example, if the activation function is sigmoid, then:

For Hidden Layers:
Consider a hidden neuron  that feeds into the output neurons. Its contribution to the loss is influenced by all neurons it connects to in the subsequent layer. The backpropagated error for neuron is given by:
that feeds into the output neurons. Its contribution to the loss is influenced by all neurons it connects to in the subsequent layer. The backpropagated error for neuron is given by:

Here,  is the derivative of the activation function at neuron .
is the derivative of the activation function at neuron .
More details for step (4): Gradient Calculation
For Each Weight:
Once you have the error signal  for a neuron, the gradient with respect to a weight
for a neuron, the gradient with respect to a weight  connected to input
connected to input  is:
is:

This shows that the gradient is directly proportional to the input, linking how much weight its contribution had on the final error.
For the Bias:
Since the bias b contributes to with a derivative of 1, the gradient for the bias is simply:

Login to view more content



 (its activation) and a weighted sum
(its activation) and a weighted sum  computed as:
computed as:

 is the target value.
is the target value. 


 that feeds into the output neurons. Its contribution to the loss is influenced by all neurons it connects to in the subsequent layer. The backpropagated error for neuron
that feeds into the output neurons. Its contribution to the loss is influenced by all neurons it connects to in the subsequent layer. The backpropagated error for neuron 
 is the derivative of the activation function at neuron
is the derivative of the activation function at neuron  for a neuron, the gradient with respect to a weight
for a neuron, the gradient with respect to a weight  connected to input
connected to input  is:
is:



 represents the receptive field size in layer
represents the receptive field size in layer  .
.  for the input layer.
for the input layer. represents the kernel size of layer
represents the kernel size of layer  represents the stride of layer
represents the stride of layer 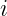 .
.