What is a Multi-Layer Perceptron (MLP)? How does it overcome Perceptron limitations?
Answer
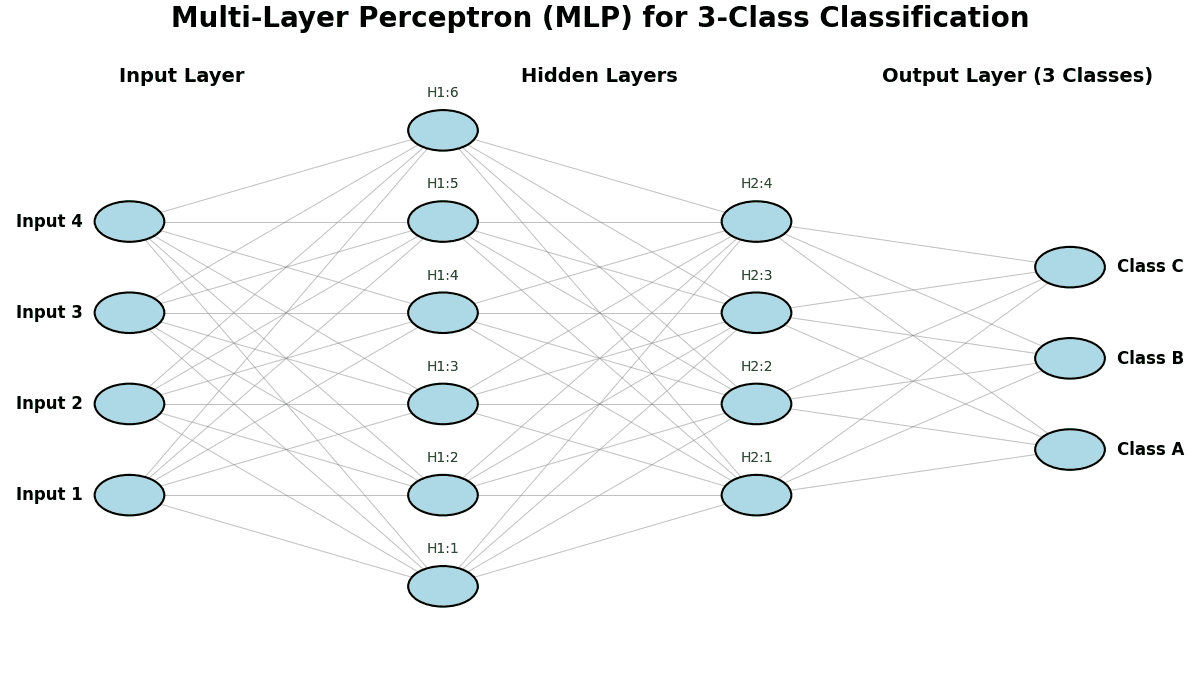
A Multi-Layer Perceptron (MLP) is a feedforward neural network with one or more hidden layers between the input and output layers. Hidden layers in MLP use non-linear activation functions (like ReLU, sigmoid, or tanh) to model complex relationships. MLP can be used for classification, regression, and function approximation. MLP is trained using backpropagation, which adjusts the weights to minimize errors.
Overcoming Limitations:
(1) Learn non-linear: Unlike a single-layer perceptron that can only solve linearly separable problems, an MLP can learn non-linear decision boundaries, handling problems such as the XOR problem.
(2) Universal Approximation: With enough neurons and layers, an MLP can approximate any continuous function, making it a powerful model for various applications.
The plot below illustrates an example of a Multi-Layer Perceptron (MLP) applied to a classification problem.

 is the predicted output (0 or 1)
is the predicted output (0 or 1) is the weight vector
is the weight vector is the input vector
is the input vector is the bias term
is the bias term is the activation function (typically a step function)
is the activation function (typically a step function)

 represents the original value of the feature.
represents the original value of the feature. represents the minimum value of the feature in the dataset.
represents the minimum value of the feature in the dataset. represents the maximum value of the feature in the dataset.
represents the maximum value of the feature in the dataset.
 represents the mean of the feature in the dataset.
represents the mean of the feature in the dataset. represents the standard deviation of the feature in the dataset.
represents the standard deviation of the feature in the dataset.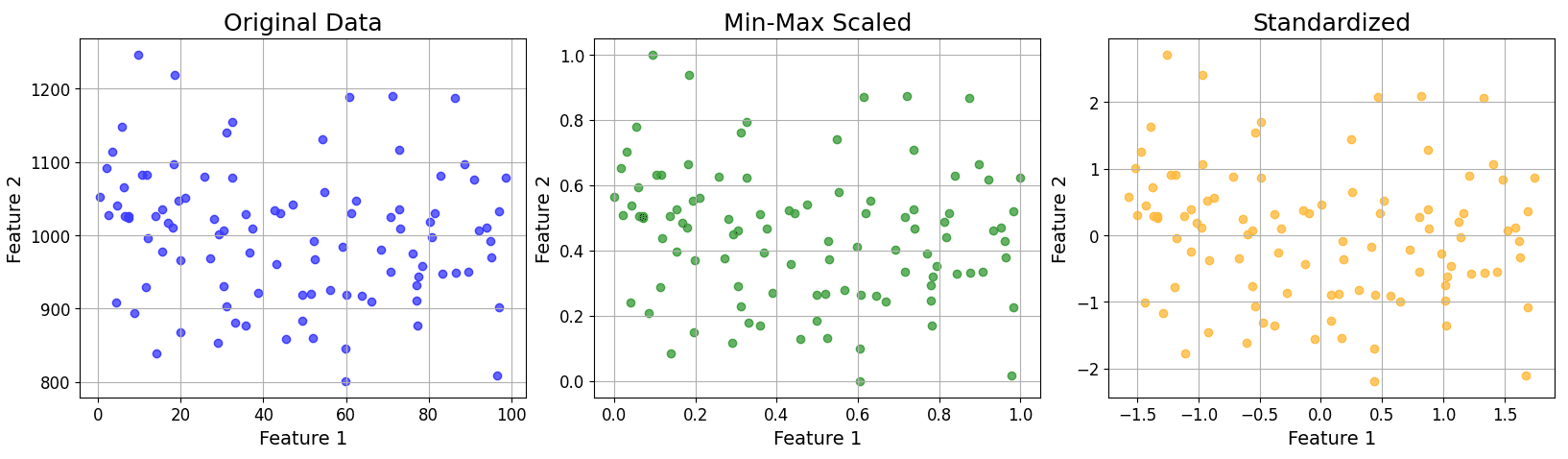


 for input
for input  :
:



 , channel
, channel  , height
, height  , and width
, and width  is the height of the feature map (number of rows per channel).
is the height of the feature map (number of rows per channel). is the width of the feature map (number of columns per channel).
is the width of the feature map (number of columns per channel). is the mean of all spatial values in channel
is the mean of all spatial values in channel  is the variance of spatial values in channel
is the variance of spatial values in channel  is the normalized value after subtracting the mean and dividing by the standard deviation.
is the normalized value after subtracting the mean and dividing by the standard deviation. is a small constant added to the denominator to prevent division by zero and improve numerical stability.
is a small constant added to the denominator to prevent division by zero and improve numerical stability. is a learnable scale parameter for channel
is a learnable scale parameter for channel  is a learnable shift parameter for channel
is a learnable shift parameter for channel 