Please explain how KNN classification works.
Answer
K-Nearest Neighbors (KNN) is a simple, non-parametric algorithm that predicts a label by majority vote among the  nearest neighbors of a test point, using a chosen distance metric. It is intuitive and effective for small datasets, though less efficient on large-scale data.
nearest neighbors of a test point, using a chosen distance metric. It is intuitive and effective for small datasets, though less efficient on large-scale data.
(1) Instance-based method: KNN doesn’t learn an explicit model; it stores the training data and makes predictions based on similarity.
(2) Distance-based classification: For a test point  , it computes the distance to every training point (e.g., Euclidean distance).
, it computes the distance to every training point (e.g., Euclidean distance).
(3) Majority vote: It selects the  closest neighbors and assigns the label that appears most frequently among them.
closest neighbors and assigns the label that appears most frequently among them.
(4) Sensitive to K and distance metric: The performance depends on the choice of and how distance is measured (Euclidean, Manhattan, etc.).
(5) No training phase: All computation happens during prediction (also called lazy learning).
Below is the equation for Euclidean Distance calculation:
Where: and
and  are the
are the 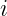 th features of the new and training points, respectively.
th features of the new and training points, respectively. is the number of features
is the number of features
Below is the equation for the Voting Rule in KNN classification:
Where: is the predicted class label for the query point.
is the predicted class label for the query point. represents the set of all possible classes. is the number of nearest neighbors considered. is the class label of the i-th neighbor.
represents the set of all possible classes. is the number of nearest neighbors considered. is the class label of the i-th neighbor. is an indicator function, returning 1 if the neighbor’s class is
is an indicator function, returning 1 if the neighbor’s class is  , and 0 otherwise.
, and 0 otherwise.
The example below shows KNN for classification.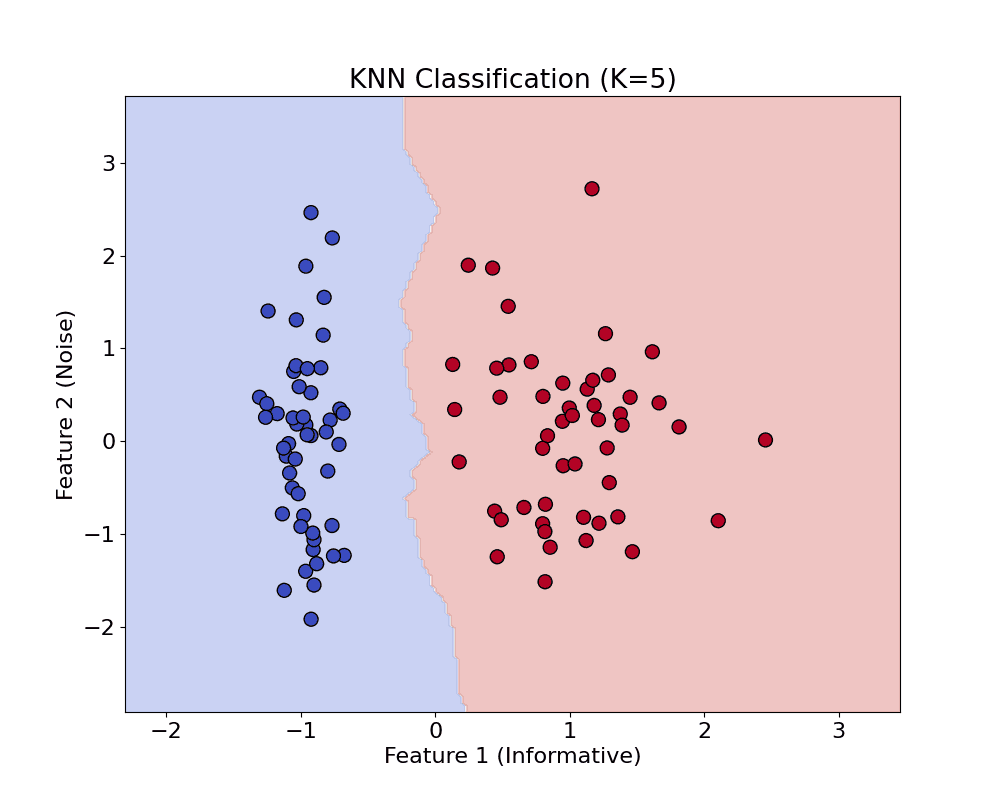
Leave a Reply