What is the difference between 2D and 3D convolutions, and when would you use each?
Answer
A 2D convolution slides a kernel across height and width, while aggregating all input channels at each spatial location. A 3D convolution slides across depth or time as well as height and width, so it learns joint spatiotemporal or volumetric features. Use 2D convolution for ordinary images, per-frame video processing, or slice-wise analysis when cross-slice context is unnecessary. Use 3D convolution for videos, CT/MRI volumes, or occupancy grids when local relationships along the third axis carry essential information and the additional memory and compute are affordable.
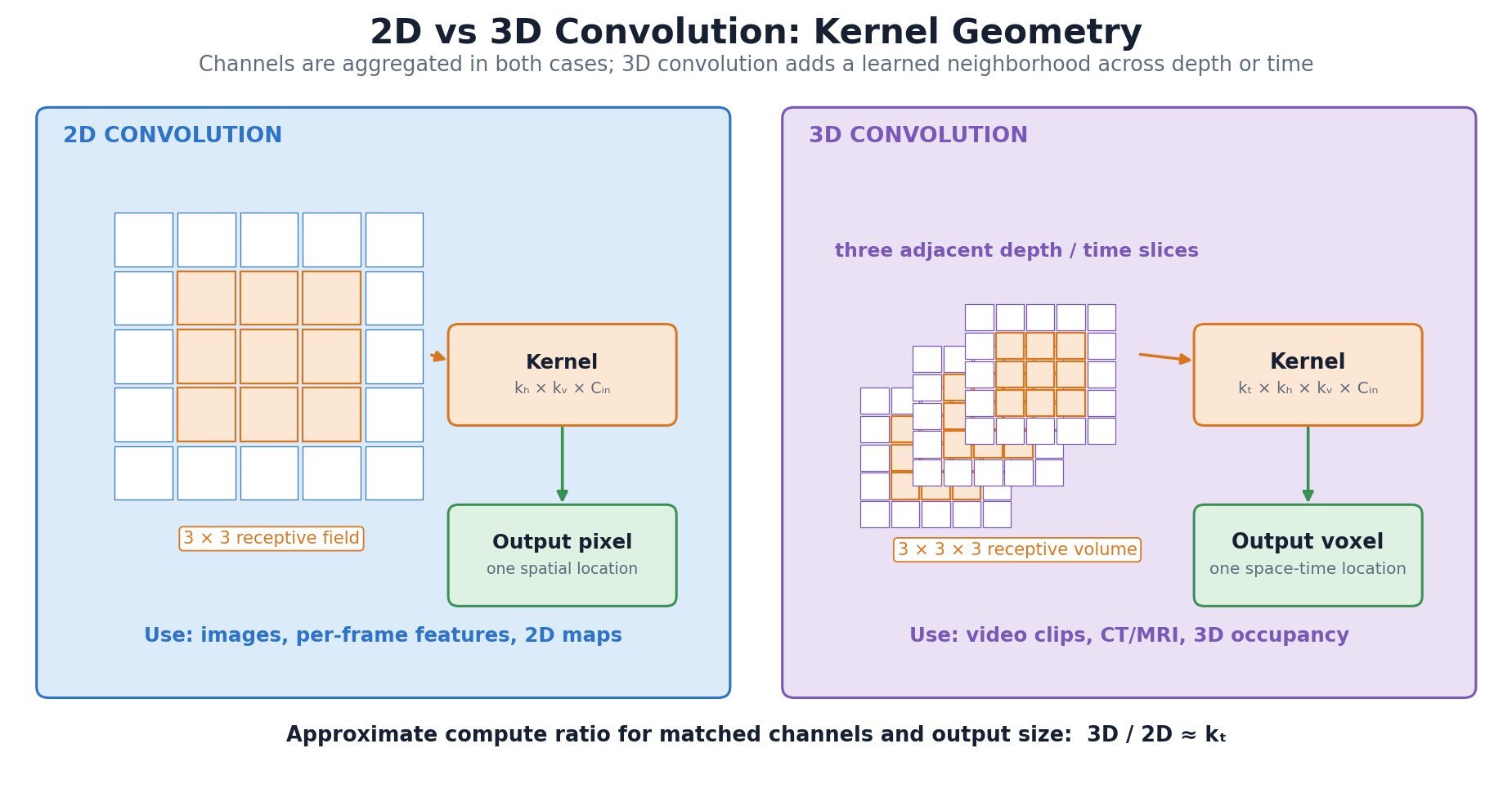
Figure 1: Kernel geometry and output formation for 2D spatial convolution and 3D spatiotemporal convolution.
(1) Kernel Geometry: A 2D kernel has spatial extent  ; a 3D kernel adds
; a 3D kernel adds  and jointly traverses depth or time.
and jointly traverses depth or time.
(2) Data Semantics: The third axis should represent an ordered neighborhood such as adjacent frames or slices, not an unordered feature channel.
(3) Trade-off: 3D convolution captures motion or volumetric continuity directly but costs roughly times more than a comparable 2D layer and stores larger activation volumes.
Mathematical Formulation:

Where:
 and
and  are the input and output tensors, while
are the input and output tensors, while  is the learned 3D convolution kernel.
is the learned 3D convolution kernel. indexes output channels and
indexes output channels and  indexes input channels.
indexes input channels. index output depth/time, height, and width;
index output depth/time, height, and width;  range over the kernel support along those axes.
range over the kernel support along those axes.- For a 2D convolution,
 and
and  are removed, leaving only spatial indices
are removed, leaving only spatial indices  ; stride, padding, and dilation modify each active index mapping.
; stride, padding, and dilation modify each active index mapping.
 and
and  are the input and output tensors, while
are the input and output tensors, while  is the learned 3D convolution kernel.
is the learned 3D convolution kernel. indexes output channels and
indexes output channels and  indexes input channels.
indexes input channels. index output depth/time, height, and width;
index output depth/time, height, and width;  range over the kernel support along those axes.
range over the kernel support along those axes. and
and  are removed, leaving only spatial indices
are removed, leaving only spatial indices  ; stride, padding, and dilation modify each active index mapping.
; stride, padding, and dilation modify each active index mapping.
Figure 2: Selection guide based on third-axis semantics, required context, resource budget, and deployment constraints.
 score and probability matrices in high-bandwidth memory (HBM), it loads blocks of
score and probability matrices in high-bandwidth memory (HBM), it loads blocks of  ,
,  into fast on-chip SRAM, computes attention block by block, and maintains online softmax statistics. Tiling reduces expensive HBM reads and writes, while recomputation during the backward pass can be cheaper than storing large intermediates. The mathematical result matches standard attention up to normal floating-point differences; the speedup comes from changing the execution schedule, not from approximating attention.
into fast on-chip SRAM, computes attention block by block, and maintains online softmax statistics. Tiling reduces expensive HBM reads and writes, while recomputation during the backward pass can be cheaper than storing large intermediates. The mathematical result matches standard attention up to normal floating-point differences; the speedup comes from changing the execution schedule, not from approximating attention.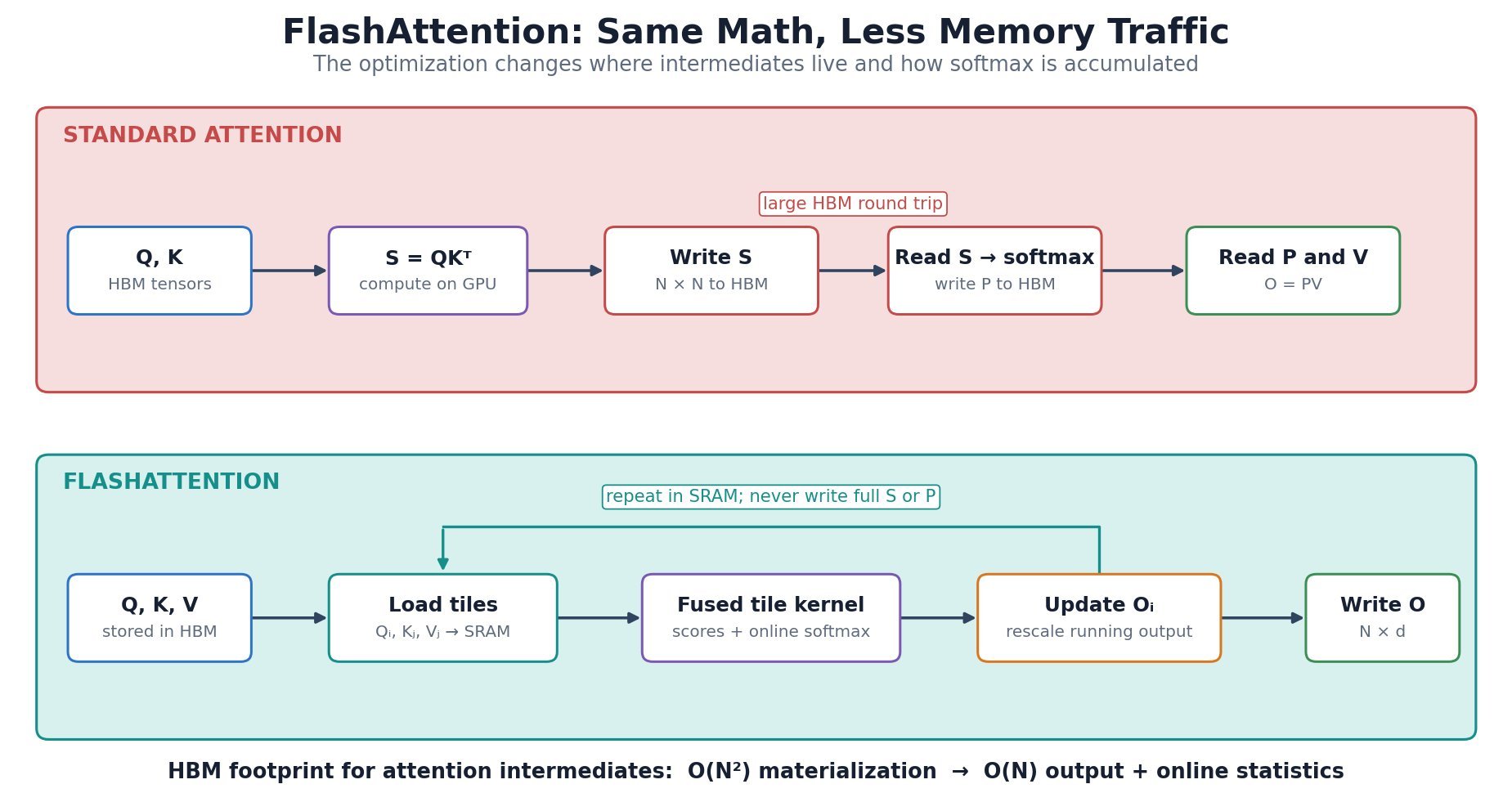
 tile to update the output without retaining previous score blocks.
tile to update the output without retaining previous score blocks.

 indexes key/value tiles,
indexes key/value tiles, 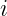 indexes a query row, and
indexes a query row, and  indexes keys inside tile
indexes keys inside tile  is the scaled score between query row
is the scaled score between query row  and key row
and key row  , with head width
, with head width  is the running row maximum after tile
is the running row maximum after tile  .
. is the running softmax denominator, initialized with
is the running softmax denominator, initialized with  ; the exponential factors rescale earlier partial sums when the maximum changes.
; the exponential factors rescale earlier partial sums when the maximum changes.
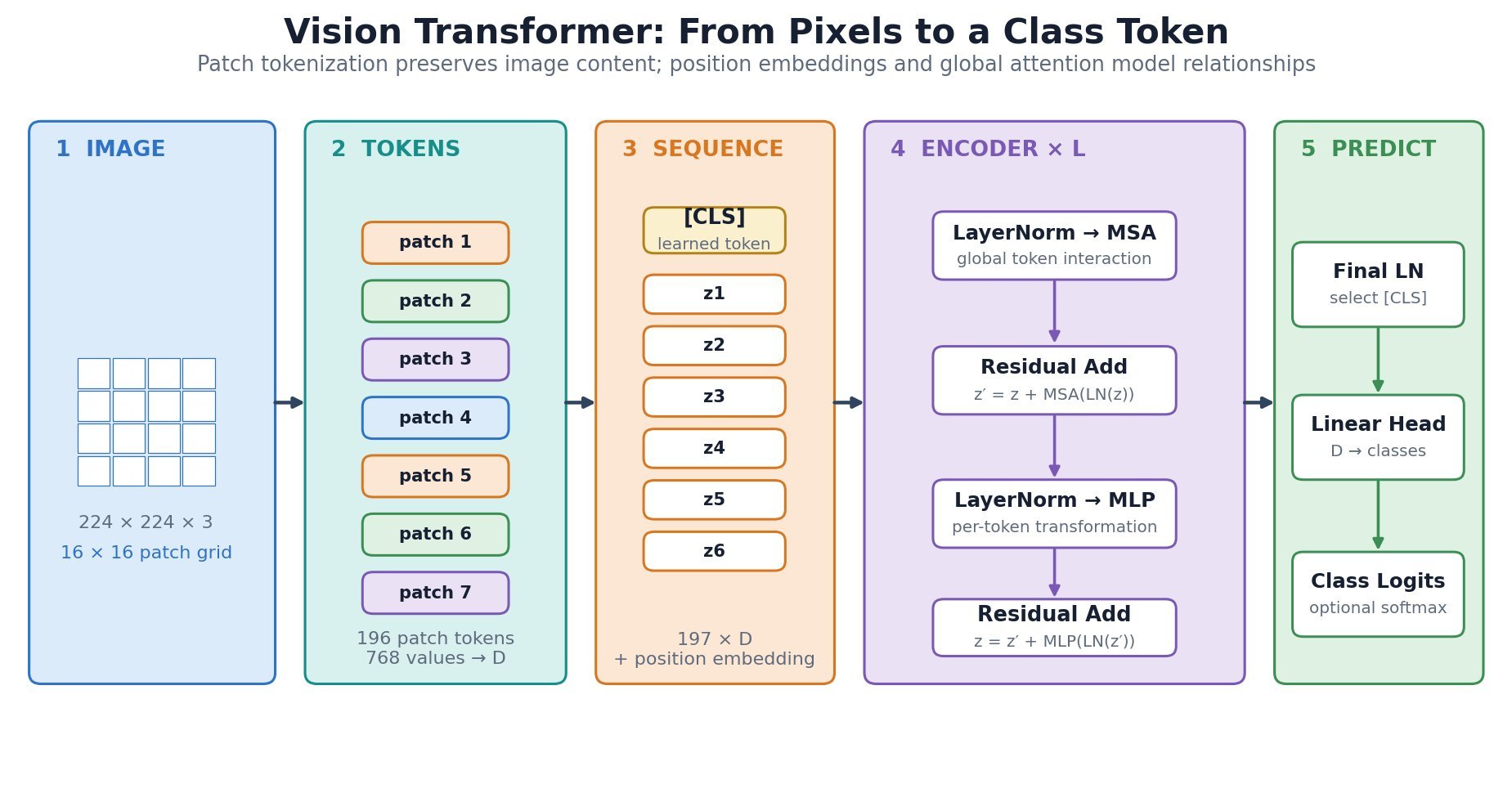
 is divided into
is divided into  non-overlapping
non-overlapping  patches; each flattened patch is projected to width
patches; each flattened patch is projected to width  .
.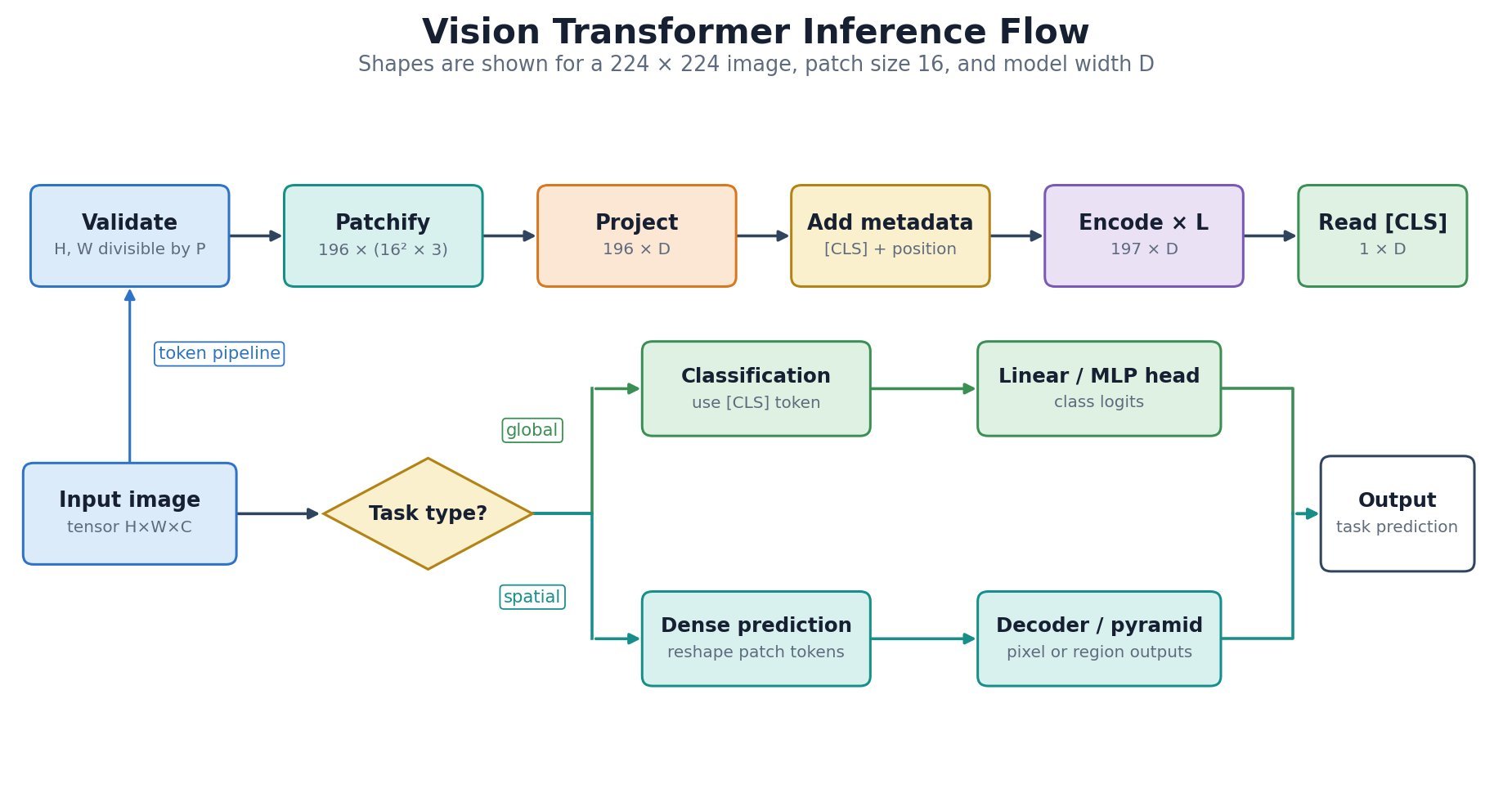
![z_0=[x_{\mathrm{cls}};x_p^1E;x_p^2E;\ldots;x_p^NE]+E_{\mathrm{pos}}](https://s0.wp.com/latex.php?latex=z_0%3D%5Bx_%7B%5Cmathrm%7Bcls%7D%7D%3Bx_p%5E1E%3Bx_p%5E2E%3B%5Cldots%3Bx_p%5ENE%5D%2BE_%7B%5Cmathrm%7Bpos%7D%7D&bg=ffffff&fg=000&s=3&c=20201002)

 is the initial token sequence supplied to the Transformer encoder.
is the initial token sequence supplied to the Transformer encoder. is the learned class token, and
is the learned class token, and  is flattened image patch
is flattened image patch  projects each
projects each  patch to width
patch to width  supplies positional embeddings.
supplies positional embeddings. , width
, width  , and channel count
, and channel count  .
. is the per-head query/key width.
is the per-head query/key width. to
to  where K is a small constant (typically 4). This makes it ideal for high-resolution feature maps in object detection where full attention is computationally prohibitive — for a 1024×1024 feature map, standard attention requires ~1M operations per head while deformable attention needs only ~4K.
where K is a small constant (typically 4). This makes it ideal for high-resolution feature maps in object detection where full attention is computationally prohibitive — for a 1024×1024 feature map, standard attention requires ~1M operations per head while deformable attention needs only ~4K.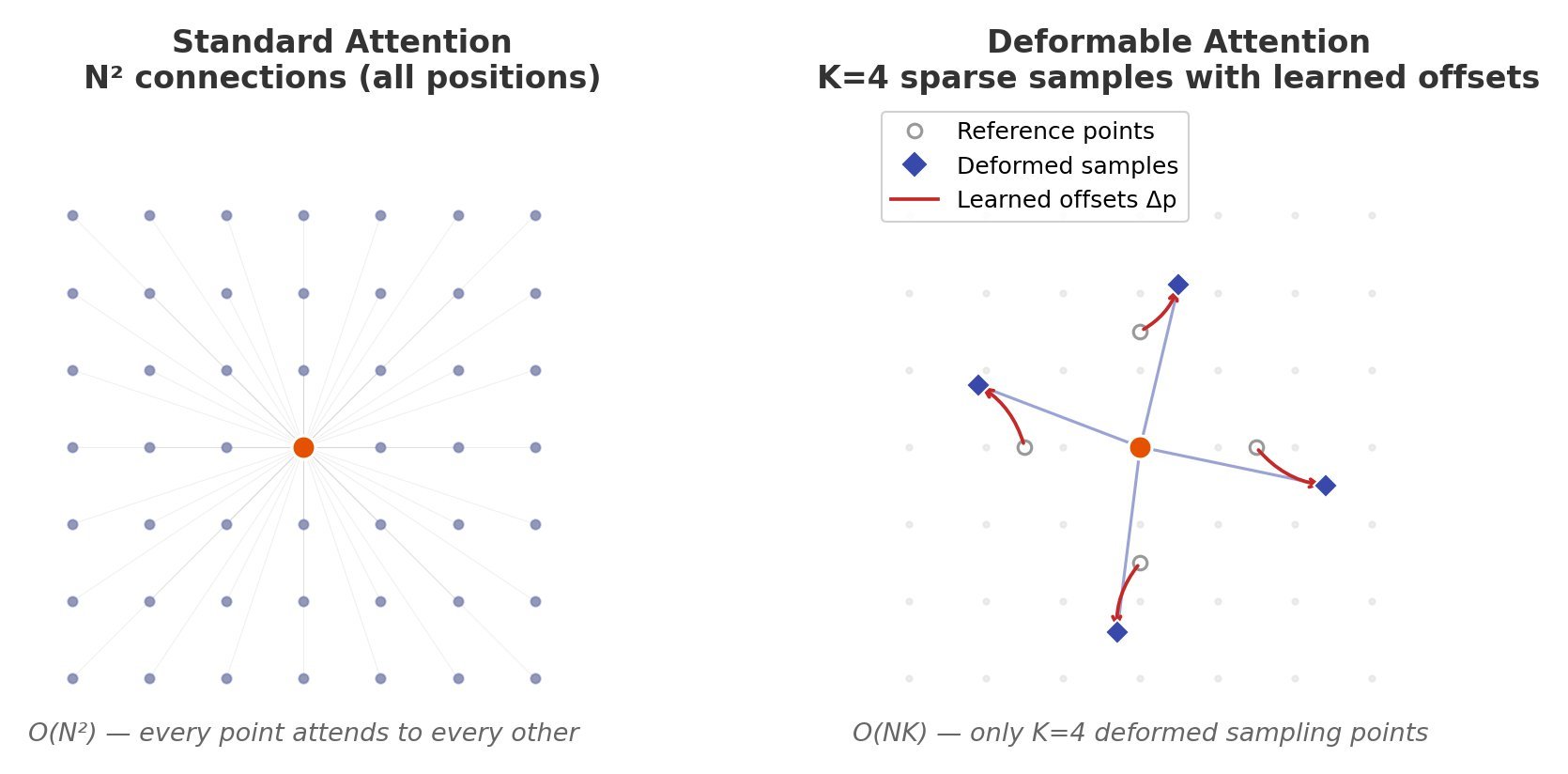
 positions, deformable attention samples only K reference points per query, typically K=4 or 8, reducing the key-value set from N to K.
positions, deformable attention samples only K reference points per query, typically K=4 or 8, reducing the key-value set from N to K. offsets from each reference point
offsets from each reference point  using a lightweight linear layer on query features, requiring only
using a lightweight linear layer on query features, requiring only  additional computation where C is channel dimension.
additional computation where C is channel dimension.
![y(p) = \sum_{m=1}^{M} W_m \left[ \sum_{k=1}^{K} A_{mk} \cdot W_m' x(p + p_k + \Delta p_{mk}) \right]](https://s0.wp.com/latex.php?latex=y%28p%29+%3D+%5Csum_%7Bm%3D1%7D%5E%7BM%7D+W_m+%5Cleft%5B+%5Csum_%7Bk%3D1%7D%5E%7BK%7D+A_%7Bmk%7D+%5Ccdot+W_m%27+x%28p+%2B+p_k+%2B+%5CDelta+p_%7Bmk%7D%29+%5Cright%5D&bg=ffffff&fg=000&s=3&c=20201002)
 is the reference position (query location on the feature map)
is the reference position (query location on the feature map) is the number of attention heads
is the number of attention heads is the number of sampled keys per head (typically 4)
is the number of sampled keys per head (typically 4) are fixed reference offsets (uniformly initialized)
are fixed reference offsets (uniformly initialized) are learned deformable offsets (2D, predicted per head per key)
are learned deformable offsets (2D, predicted per head per key) is the attention weight (normalized, not from softmax over all positions)
is the attention weight (normalized, not from softmax over all positions) are projection matrices for each head
are projection matrices for each head , where
, where  . The attention weights
. The attention weights  are computed via a separate softmax over only K elements, not the full N positions. In Deformable DETR, multi-scale deformable attention extends this to sample across multiple feature map resolutions simultaneously, enabling the model to capture both small and large objects efficiently.
are computed via a separate softmax over only K elements, not the full N positions. In Deformable DETR, multi-scale deformable attention extends this to sample across multiple feature map resolutions simultaneously, enabling the model to capture both small and large objects efficiently.
 is multiplied by a sigmoid gate
is multiplied by a sigmoid gate  where
where  is a head-specific projection.
is a head-specific projection.![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000&s=2&c=20201002) , and empirical measurements show mean gate activation of ~0.116, meaning most heads are heavily suppressed — introducing beneficial sparsity without hard pruning.
, and empirical measurements show mean gate activation of ~0.116, meaning most heads are heavily suppressed — introducing beneficial sparsity without hard pruning.


 is the output of the
is the output of the ![g_i \in [0, 1]](https://s0.wp.com/latex.php?latex=+g_i+%5Cin+%5B0%2C+1%5D+&bg=ffffff&fg=000&s=2&c=20201002) is the head-specific gate score
is the head-specific gate score is a learned projection from query to scalar gate
is a learned projection from query to scalar gate is the sigmoid function
is the sigmoid function denotes element-wise multiplication
denotes element-wise multiplication is the standard output projection
is the standard output projection adds only
adds only  parameters per head — a negligible overhead of ~0.1% of total model parameters — yet significantly improves long-context performance. On the RULER benchmark at 128K context length, gated attention improves needle-in-haystack retrieval accuracy from ~72% to ~94% compared to standard attention.
parameters per head — a negligible overhead of ~0.1% of total model parameters — yet significantly improves long-context performance. On the RULER benchmark at 128K context length, gated attention improves needle-in-haystack retrieval accuracy from ~72% to ~94% compared to standard attention.










 represents the absolute position of the token in the sequence.
represents the absolute position of the token in the sequence.  represents the base frequency/rotation angle.
represents the base frequency/rotation angle.  represent the components of the embedding vector.
represent the components of the embedding vector.

 represents the i-th model weight
represents the i-th model weight controls the strength of sparsity
controls the strength of sparsity
 is the neuron input.
is the neuron input.