The ML system for spam detection is a real-time classification pipeline. It begins with data collection and preprocessing (features extracted from text and metadata). A Supervised Learning model (e.g., Logistic Regression, Gradient Boosting, or a Neural Network) is trained on labeled data. The model is deployed as a real-time prediction service that intercepts incoming emails. Performance is monitored using metrics like precision and recall, and the model is continuously retrained to adapt to new spamming techniques (concept drift).
(1) Objectives and Metrics:
The goal is to classify incoming emails as spam or not spam in real time, minimizing false positives (mislabeling important emails as spam) while maintaining high recall (catching most spam).
(a) Primary Metric: Precision is critical. A high False Positive rate (marking legitimate emails as spam) is highly detrimental to user experience.
(b) Secondary Metric: Recall is also important to ensure most spam is caught (low False Negative rate).
(c) Evaluation Metric: The F1-score or Area Under the ROC Curve (AUC) provides a good balance.
(2) Data Collection:
(a) Sources: Historical emails labeled by users (spam / not spam). External spam datasets (e.g., Enron spam dataset).
(b) Features to collect:
Email text: subject and body.
Metadata: sender address, domain reputation, number of recipients.
Other: Embedded links, presence of attachments, message frequency.
(3) Data Preprocessing and Feature Engineering:
(a) Text cleaning: Remove HTML tags, URLs, punctuation.
(b) Tokenization: Split text into words/subwords (WordPiece).
(c) Textual Features Vectorization:
Classical: Term Frequency-Inverse Document Frequency (TF-IDF) or bag-of-words.
Modern: Pretrained embeddings (BERT, DistilBERT).
(d) Metadata Features Engineering:
Sender reputation score.
Ratio of uppercase words or spam keywords.
Number of links or suspicious domains.
(4) Model Selection and Training:
(a) Baseline Models: Start with Naive Bayes or Logistic Regression.
(b) Advanced Models: Ensemble methods like Random Forest or XGBoost, deep learning with CNNs/RNNs on text sequences, or pre-trained transformers like BERT for state-of-the-art performance.
(c) Training Process: Split the dataset for train/test; Use K-Fold Cross-Validation on a historical dataset, and maintain a separate held-out test set for final evaluation. For large-scale, distributed training with TensorFlow or PyTorch on GPUs.
(5) Deployment & Inference:
(a) Deployment Architecture: The trained model is saved (e.g., in a model registry) and loaded into a low-latency prediction service.
(b) Inference Flow:
The inference flow is shown in the figure below.

Step 1: The mail server receives incoming email.
Step 2: The email content and headers are passed to the Spam Prediction Service API.
Step 3: The service performs real-time feature extraction and feeds the feature vector to the loaded model.
Step 4: The model returns a spam probability score (e.g., 0.95).
Step 5: A threshold is applied (e.g., a score greater than 0.8 is classified as spam).
Final Action: If classified as spam, the email is moved to the user’s spam folder; otherwise, it goes to the inbox.
(6) Maintenance and Monitoring
One critical part of a spam system is its ability to adapt to Concept Drift—spammers constantly change their tactics.
(a) Performance Monitoring: Track and alert on key metrics.
User Feedback: Explicit ‘Mark as Spam’ or ‘Not Spam’ actions are the best source of new labeled data.
Model Accuracy: Monitor Precision, Recall, and F1-score daily.
Prediction Drift: Monitor the distribution of prediction scores. A sudden drop in the average predicted spam score might indicate the model is no longer effective.
(b) Retraining Pipeline: Implement a Continuous Training pipeline.
 , where
, where  is the sequence length. For long document classification (e.g., thousands of tokens), this quadratic scaling becomes prohibitive.
is the sequence length. For long document classification (e.g., thousands of tokens), this quadratic scaling becomes prohibitive.







 to reveal more information about class similarities:
to reveal more information about class similarities:
 : Raw score (logit) for the i-th class.
: Raw score (logit) for the i-th class. : Total number of classes in the classification problem.
: Total number of classes in the classification problem. : Temperature parameter (>0) used to soften the probabilities. Higher
: Temperature parameter (>0) used to soften the probabilities. Higher 



 = number of input units
= number of input units = number of output units
= number of output units means weights are sampled from a normal (Gaussian) distribution with mean
means weights are sampled from a normal (Gaussian) distribution with mean  and variance
and variance  .
. means weights are sampled from a uniform distribution in the range
means weights are sampled from a uniform distribution in the range ![[a, b]](https://s0.wp.com/latex.php?latex=+%5Ba%2C+b%5D+&bg=ffffff&fg=000&s=2&c=20201002) .
.



 is the 1st moment (mean of gradients).
is the 1st moment (mean of gradients). is the gradient at step
is the gradient at step  .
. controls momentum (default: 0.9).
controls momentum (default: 0.9).
 is the 2nd moment (variance of gradients).
is the 2nd moment (variance of gradients). controls smoothing of squared gradients (default: 0.999).
controls smoothing of squared gradients (default: 0.999).

 is the bias-corrected 1st moment.
is the bias-corrected 1st moment. is the bias-corrected 2nd moment.
is the bias-corrected 2nd moment. ,
,  are the exponential decay raised to step
are the exponential decay raised to step  ) and divides by the square root of the bias-corrected second moment (
) and divides by the square root of the bias-corrected second moment (
 are model parameters.
are model parameters.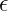 prevents division by zero.
prevents division by zero.
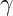 to suppress easy-example gradients and focus learning on hard examples, making it preferable when many easy negatives overwhelm training but requiring careful tuning to avoid amplifying label noise.
to suppress easy-example gradients and focus learning on hard examples, making it preferable when many easy negatives overwhelm training but requiring careful tuning to avoid amplifying label noise.
 is the model probability for the ground-truth class;
is the model probability for the ground-truth class; is the per-class weight for class t.
is the per-class weight for class t.
 is the focusing parameter that down-weights easy examples.
is the focusing parameter that down-weights easy examples.

 and an optional balancing weight
and an optional balancing weight  is an optional class-balancing weight for class t.
is an optional class-balancing weight for class t.
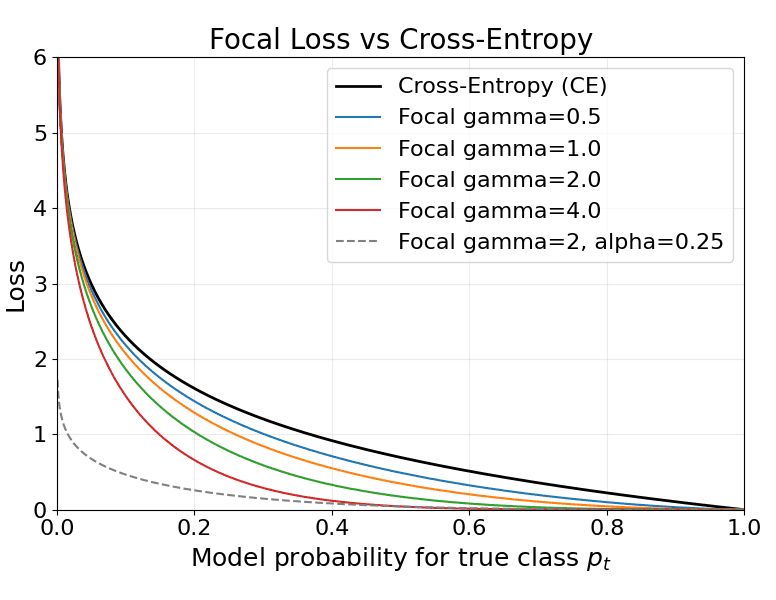
 →
→  ) before reducing it back?
) before reducing it back? ) to enhance the model’s ability to learn complex, non-linear feature interactions, then reduces it back to maintain compatibility with other layers. This design acts as a bottleneck, balancing expressiveness and efficiency, and has been empirically shown to boost performance in large-scale models.
) to enhance the model’s ability to learn complex, non-linear feature interactions, then reduces it back to maintain compatibility with other layers. This design acts as a bottleneck, balancing expressiveness and efficiency, and has been empirically shown to boost performance in large-scale models. allows the FFN to capture richer nonlinear transformations.
allows the FFN to capture richer nonlinear transformations.
 is the input vector.
is the input vector. expands the dimension.
expands the dimension. is a non-linear activation (e.g., ReLU/GELU).
is a non-linear activation (e.g., ReLU/GELU). projects back down.
projects back down.