In the context of designing a K-Nearest Neighbors (KNN) model, can you explain your approach to selecting the value of K?
Answer
Selecting the optimal value for ‘K’ in a K-Nearest Neighbors (KNN) model is crucial as it significantly impacts the model’s performance.
(1) Bias-Variance Tradeoff: The choice of K involves balancing bias and variance.
A small  (e.g., 1) leads to low bias and high variance, often resulting in overfitting.
(e.g., 1) leads to low bias and high variance, often resulting in overfitting.
A large increases bias but reduces variance, potentially underfitting the data.
(2) Use Odd Values for Classification: In binary classification, odd avoids ties.
(3) Cross-Validation Combined with Grid Search: Use k-fold cross-validation to evaluate performance across multiple values of , and select the one that minimizes the validation error.
Cross-Validation Error can be calculated by the below equation.
Where: is the actual outcome for the i‑th instance.
is the actual outcome for the i‑th instance. represents the predicted value using neighbors.
represents the predicted value using neighbors. is the total number of validation samples.
is the total number of validation samples. is a loss function.
is a loss function.
(4) Domain Knowledge: In some cases, prior knowledge for the data distribution can help select a reasonable range of .
The example below apply k-fold cross-validation with grid search for K selection in one KNN regression task.

 is the predicted value for the query point.
is the predicted value for the query point.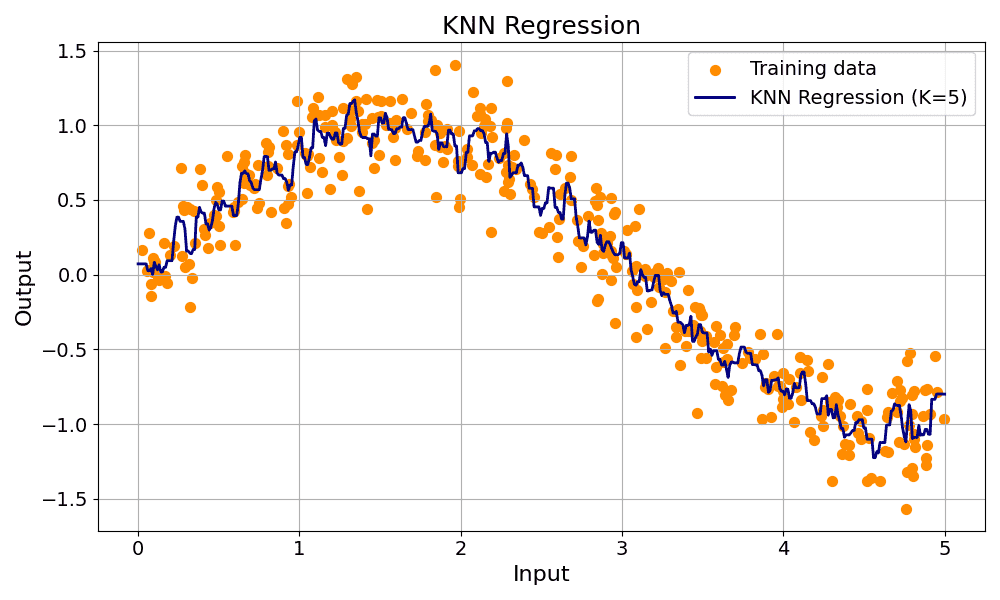
 nearest neighbors of a test point, using a chosen distance metric. It is intuitive and effective for small datasets, though less efficient on large-scale data.
nearest neighbors of a test point, using a chosen distance metric. It is intuitive and effective for small datasets, though less efficient on large-scale data. , it computes the distance to every training point (e.g., Euclidean distance).
, it computes the distance to every training point (e.g., Euclidean distance).
 and
and 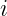 th features of the new and training points, respectively.
th features of the new and training points, respectively. is the number of features
is the number of features
 is the predicted class label for the query point.
is the predicted class label for the query point. represents the set of all possible classes.
represents the set of all possible classes. is an indicator function, returning 1 if the neighbor’s class is
is an indicator function, returning 1 if the neighbor’s class is  , and 0 otherwise.
, and 0 otherwise.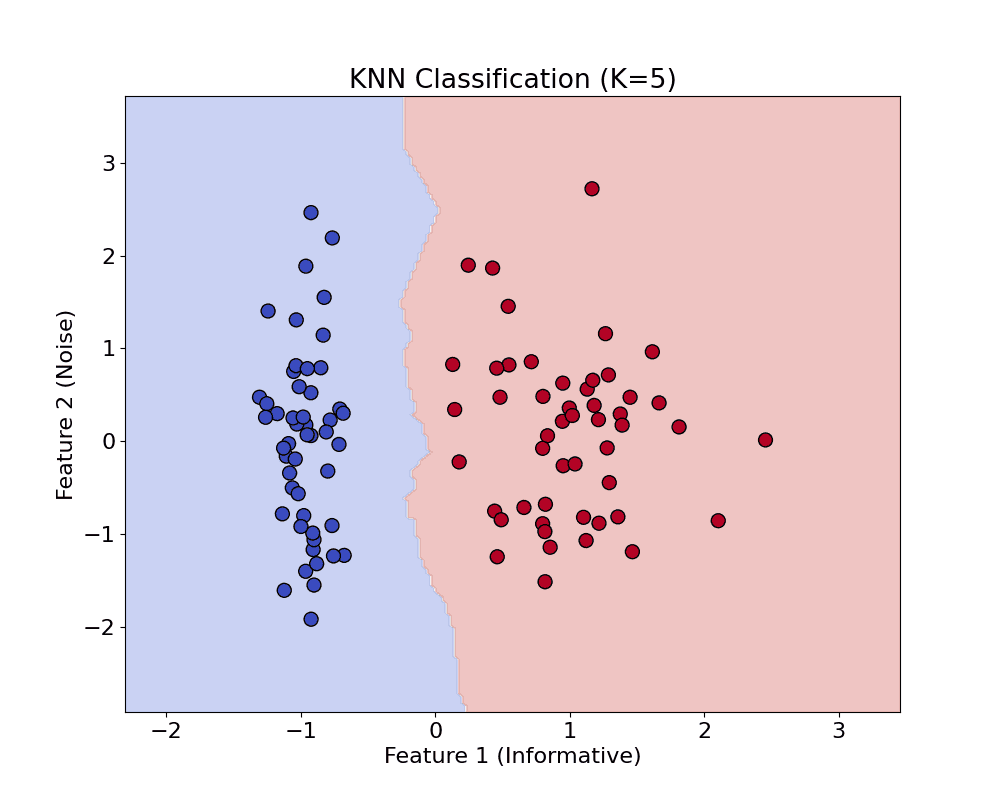

 is the true label,
is the true label, is the raw model output.
is the raw model output.
 , meaning the point is correctly classified with margin.
, meaning the point is correctly classified with margin. , the point is either inside the margin or misclassified.
, the point is either inside the margin or misclassified.
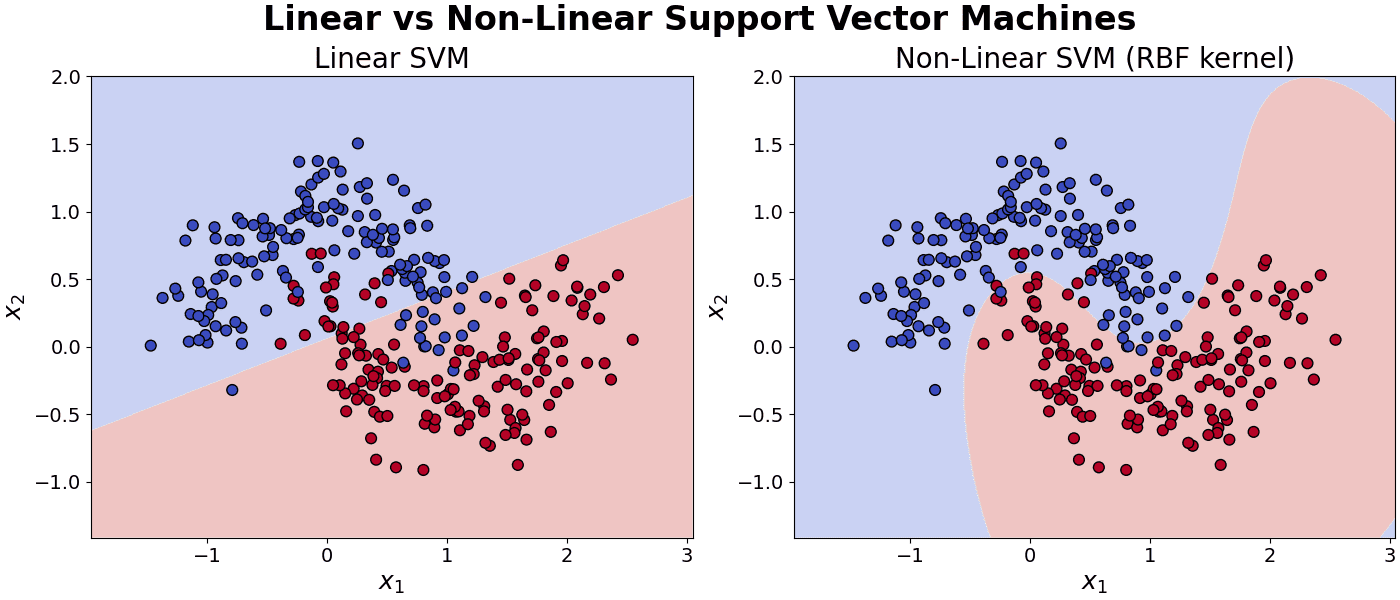
 are input vectors.
are input vectors. controls the scale of the inner product.
controls the scale of the inner product. is the degree of the polynomial.
is the degree of the polynomial.
 is the squared Euclidean distance between the vectors.
is the squared Euclidean distance between the vectors. is a parameter that controls the width of the Gaussian (spread).
is a parameter that controls the width of the Gaussian (spread).
 is a bias term.
is a bias term.

 is the weight vector.
is the weight vector. is the bias term.
is the bias term.
 returns +1 if the argument is ≥ 0, and −1 otherwise.
returns +1 if the argument is ≥ 0, and −1 otherwise.

 is the class label for the i-th data point.
is the class label for the i-th data point. is the i-th feature vector.
is the i-th feature vector.



 is the input feature vector,
is the input feature vector, is the weight vector, and
is the weight vector, and is the bias term.
is the bias term.
